tokenizer的原理I
本文最后更新于 2024年7月29日晚上7点24分
tokenizer的原理详解I
相关术语
什么是token:
token是文本或序列数据中的最小离散单元。在自然语言处理中,一个token可以是一个单词、一个子词(如字母、音节或子词片段),或一个字符,取决于任务和数据的预处理方式。
例如,把单词作为最小离散单元,句子”I love deep learning”可以被拆分成4个单词 tokens:[“I”, “love”, “deep”, “learning”]。什么是tokenization:
tokenization的中文意思是分词,就是把文本划分为一个个tokens的过程。什么是tokenizer:
tokenizer是分词器,或者标记器。是模型中将文本转换为tokens的模块。和tokenization差不多。什么是embedding,中文叫嵌入:
embedding就是把token映射到连续的向量空间的方法,得到的向量叫做词向量或者词嵌入。
神经网络会将文本序列中的每个token编码为向量表示,以便进行后续的计算和处理。现在除了word embedding,还有sentence embedding。这里我只讲如何实现word embedding。我感觉embedding可以是动词:把token变为向量的这个动作;也可以是名词:得到的向量称为embedding。理解它是什么含义即可。
为什么需要tokenizer
为了方便,下面的文本默认是英文文本。在很多NLP任务中,输入文本,模型无法直接对string类型的文字处理,需要把它们量化为向量。
如何把string变为向量?首先,构建词表vocabulary,词表存储的是所有常见的单元, 假设词表的长度为$L$。把输入文本切分为一个个token,每个token在词表中有一个对应的整型索引,然后把整数索引(一个在范围$0 ~ L-1$的整数),或者是一个长度为$L$的one-hot向量, 变为 $K \times 1$ 的向量, 其中$K<<L$。
此时涉及到两个问题:
- 构建词表的单元是什么,即分词粒度。是每个单词word,还是每个字母character,或者其他单元?下面介绍三种粒度。
- 整型索引如何转为向量?下面介绍一种word2vec方法,用于把token转为向量。
word-based tokenizer
为了方便理解整个过程,以word为基本单元。看看基于word的tokenizer如何实现。
首先,构建词表是英文中常见单词,假设词表总共有32000个常见的word。然后,把句子切分为一个个word,每个单词$word_i$对应一个0~31999范围的索引$word_{idx}$。如何把索引转为向量,最基本是使用one-hot方法,每个索引变为大小为32000*1的向量,对应索引位置为1,其余位置为0.比如$word_{idx}=0$对应的向量是$[1,0,0..,0,0]$.
基于word的tokenizer有缺陷:
- 词表vocabulary很大,参数多,难训练。英文中除了常见单词,还有很多生僻词,导致每个word对应的one-hot向量的size很大,后续把向量输入给模型进行训练时,参数矩阵很大,训练难。
- 容易OOV。OOV=out of vocabulary,即某些token在词表中查询不到,例如某些拼写错误的词。
character-based tokenizer
除了把word作为token单元,还可以把每个字母作为token单元。这样词表的长度=26,每个字母可以表示为一个长度为26*1的one-hot向量。
以字母为单元的缺陷很明显:
- 每个字母不具备任何意义,只有组合到一起才有意义,故以每个字母作为一个向量输入给模型,模型不一定能训练出这个句子的含义。这是最致命的,导致char-based tokenizer方法不可取。
- 一个句子包含很多字母,这样向量化后的sequence很长。
- 但是中文是可以进行character-based tokenizer的,因为每个汉字具有意义。
subword-based tokenizer
选择subword作为基本单元,频率高的word不拆分,罕见词拆分为小的有意义的subword。
对于后缀,会在前面加上一个特殊标记,比如把’tokenization’拆分为’token’和’##ization’,其中’##’标记’ization’是一个后缀。
优点:
- 词表的size适中,减少了OOV问题,模型可以理解没见过的单词,比如对pretrain这个单词,即使模型没见过,但是有pre和train两个token,模型也能理解pretrain的意思。
如何用subword算法构建词表:
最常见的是BPE方法 byte pair encoding:
参考这个: https://www.cnblogs.com/zjuhaohaoxuexi/p/15929039.html
(这里不讲如何构建词表)
词嵌入 word embedding
上面讲了三种tokenizer方法,分别是基于word,基于character和基于subword。实际代码中一般使用subword方法。
在构建好subword词表,并把句子切分为一个个subword后,如何把每个subword变为一个token向量,并且让意思相近的subword对应的向量也距离更近?词嵌入word embedding就是把subword变为词向量的过程。
假设词表长度=V,即共有V个subword。则每个subword的one-hot向量长度是 $V\times 1$.
假设词向量的size是 $K \times 1$ ,即需要把one-hot的 $V \times 1$ 向量转为长度为 $K \times 1$ 的连续向量。一般的,$K=32000,V=768$左右。可见,词向量大大缩小了向量维度,并且词向量是连续向量,不是稀疏的。
其中词向量的每个维度表示不同的含义,比如这768个维度中,维度1表示生物,维度2表示会动的物体,维度3表示颜色等等。
词嵌入的方法:
- predictive基于预测的方法。代表方法:CBoW,Skip-gram
- count-based基于计数的方法。代表方法:Glove vector
- tasked-based基于任务的方法。
主要介绍CBoW和skip-gram方法。这两个方法都是word2vec方法的具体实现。word2vec方法如字面意思,就是把word转为vector的方法,下面使用的模型很简单,轻量级网络,包含输入层+隐藏层+输出层。
CBoW方法
CBoW全称Continuous bag-of-words,CBoW和Skip-gram算法类似,都是基于局部滑动窗口的,利用了局部的上下文特征local context。
CBoW是根据上下文预测当前词。假设中心词是$w_t$, 根据其上下文$w_{t-2},w_{t-1},w_{t+1},w_{t+2}$来预测$w_t$。
模型很简单,输入向量先经过权重矩阵W,再经过权重矩阵W’,然后softmax得到输出。
输入:C个上下文单词的one-hot向量;输出:预测中心词的one-hot向量。
损失函数:CE,真实label是中心词的真实one-hot向量,预测label是中心词的$V*1$预测向量。
先看简单的,假设上下文词的个数是1,只输入一个one-hot向量,输出预测向量。
输入的 $ V \times 1 $ 向量先经过一个权重矩阵W,W的大小为 $ V \times K $,得到隐藏层向量 $ K \times 1$,再经过权重矩阵W’,size为 $ K \times V$,得到输出向量 $ V \times 1$,再经过softmax,得到概率向量,然后和中心词的真实one-hot计算CE误差。
如果上下文词的个数是C,即滑动窗口的大小为C+1,一次性输入C个上下文的one-hot,经过W矩阵,得到C个隐藏向量$\{x_1,x_2,..,x_C \}$,计算他们的求和平均值,得到$x_{mean}=\frac{x_1+x_2+..x_C}{C}$,然后经过W’和softmax得到输出。
这样,只要用足够的文本训练集,先把文本切分为subword,然后变为一个个one-hot,从头开始移动滑动窗口,每次根据上下文向量来预测中心词向量,从而训练模型权重矩阵W和W’。
训练好模型后,如果想要知道某一个subword的词向量,只需要把它的one-hot向量经过W矩阵,得到的 $ K \times 1$ 向量就是该subword的词向量。
skip-gram方法
上面的CBoW方法是输入上下文向量,预测中心词向量。
skip-gram反过来,输入中心词的one-hot向量,经过W矩阵得到 $ K \times 1$的隐藏向量,再经过W’矩阵和softmax得到预测向量 $w_{pred}$, $w_{pred}$会和$w_{t-2},w_{t-1},w_{t+1},w_{t+2}$分别计算CE loss再求和,然后反向传播更新W和W’。
CBoW和skip-gram对比
CBoW是输入多个上下文向量,经过hidden层向量后计算平均,再得到输出预测计算loss;
skip-gram是输入一个中心词向量,经过hidden层再得到输出后,与所有上下文向量计算loss,loss求和再更新梯度。或者可以理解为,把C个上下文one-hot合并为一个 $ V \times 1$ 向量,其中有C个元素是1,再和输出概率向量计算loss。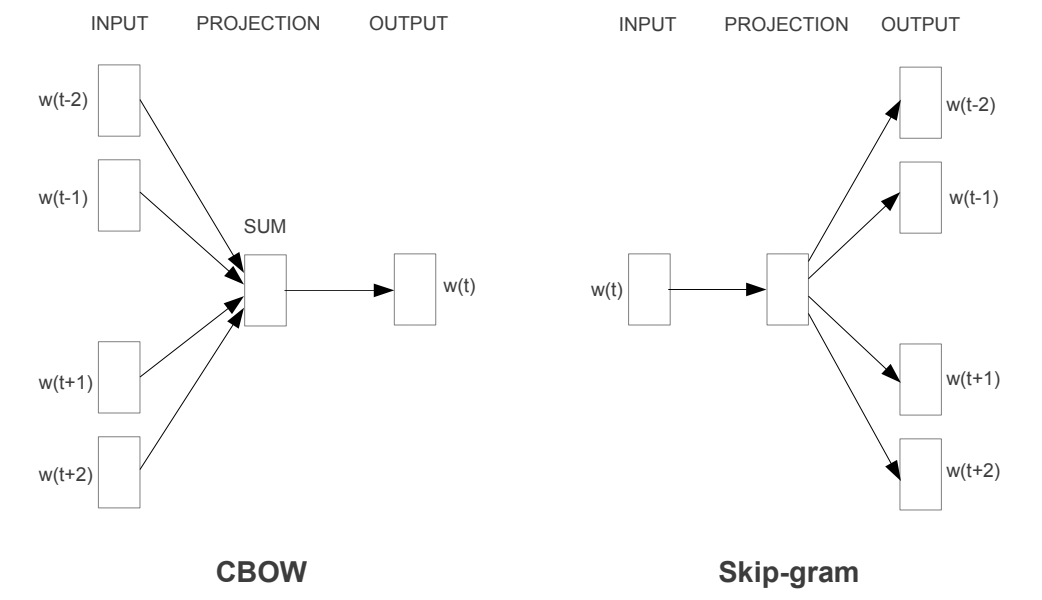
查表look up
训练好word2vec模型后,把one-hot向量跟W矩阵相乘就得到这个单词的词向量,这个过程也叫做查表look up。
通常语义相近的词出现在上下文的概率更大,word2vec模型会把两个语义相近的词的词向量训练的更接近。
参考:
CBoW和skip-gram方法的论文:Efficient Estimation of Word Representations in Vector Space