LLM-QAT论文精读
本文最后更新于 2024年7月10日凌晨1点18分
LLM-QAT论文精读
今天我们精读这篇论文:LLM-QAT: Data-Free Quantization Aware Training for Large Language Models
这篇论文实现了对通用大模型的量化,大模型的量化是指:用更少的信息表示数据,同时不损失太多准确性。通常的做法是将模型的一些参数(如权重)转换并存储为更少比特的数据类型。例如,将权重参数由16位浮点数转为8位整数,转换后的数字将会只需要一半的存储空间,同时因为精度降低,计算被简化,推理速度也会加快。
具体的,关于大模型量化的基础原理可以看这篇博客“大模型量化技术的原理和代码实现”。
论文全文翻译
Abstract
几种post-training quantization方法已经应用于大型语言模型(LLM),并且在8位精度下表现良好。我们发现这些方法在更低的位精度下会失效,因此我们研究了量化感知训练quantization aware training for LLMs(LLM-QAT),以进一步推进量化水平。
我们提出了一种无需数据的蒸馏方法(data-free distillation method),该方法利用预训练模型生成的输出,从而更好地保留了原始输出分布,并且可以独立于其训练数据对任何生成模型进行量化,类似于训练后量化方法。
除了量化权重和激活值外,我们还量化了KV缓存,这对于在当前模型规模下提高吞吐量和支持长序列依赖性至关重要。我们在7B、13B和30B大小的LLaMA模型上进行了实验,量化水平最低达4位。我们观察到,在低位设置下,相较于无需训练的方法,我们的量化方法有显著的改进。
1 Introduction
继GPT-3(Brown等,2020)之后,OPT(Zhang等,2022)、PALM(Chowdhery等,2022)、BLOOM(Scao等,2022)、Chinchilla(Hoffmann等,2022)和LLaMA(Touvron等,2023)等多个大型语言模型(LLM)家族已经证明,增加模型规模能够提升模型能力。因此,拥有数百亿甚至数千亿参数的语言模型已经成为当今AI领域的常态。尽管LLM的兴起令人振奋,但由于其巨大的计算成本和环境足迹,如何将这些模型服务于数十亿用户仍面临重大挑战。
幸运的是,越来越多的研究致力于准确量化大型语言模型(LLM),多项近期工作(Xiao等,2022;Yao等,2022)专注于权重和激活的8位训练后量化,并在几乎没有精度损失的情况下取得了成功。然而,一个拥有650亿参数的LLaMA模型,仅其权重就占用了65GB的GPU内存。此外,用于存储注意力层激活值的键值(KV)缓存可以轻易达到数十GB,并且在当今常见的长序列长度应用中成为吞吐量瓶颈。上述工作并没有考虑同时对KV缓存、权重和激活进行量化。不幸的是,最先进的训练后量化方法在超过8位时质量显著下降。对于更高的量化水平,我们发现有必要使用量化感知训练(QAT)。
据我们所知,LLM的量化感知训练(QAT)尚未被研究。这可以理解,主要有两个原因。首先,LLM的训练在技术上非常困难且资源密集。其次,QAT需要训练数据,而对于LLM来说,这些数据难以获得。预训练数据的庞大规模和多样性本身就是一个障碍。预处理可能成本高昂,更糟的是,由于法律限制,有些数据可能根本无法获得。越来越普遍的做法是分阶段训练LLM,涉及指令调优和强化学习(Ouyang等,2022),这在QAT期间很难复制。在这项工作中,我们通过使用LLM自身生成的数据进行知识蒸馏(knowledge distillation),绕过了这个问题。这种简单的解决方案,我们称之为无数据知识蒸馏,适用于任何生成模型,而不管原始训练数据是否可用。我们展示了这种方法更能保留原始模型的输出分布,甚至比在原始训练集的大子集上训练更好。此外,我们只需使用一小部分(10万)采样数据就能成功蒸馏量化模型,从而保持合理的计算成本。我们所有的实验都在单个8-GPU训练节点上进行。
因此,我们能够将7B、13B和30B的LLaMA模型的权重和KV缓存量化到4位。在这方面,我们的方法在质量上相对于训练后量化显示出显著提升。值得注意的是,采用QAT的大模型在性能上优于使用16位浮点表示的小模型,尽管它们的模型规模相似。此外,我们成功地将激活值量化到6位精度,超越了现有方法的可能性。有关我们实验结果的全面分析和详细研究,请参见第3节。
总而言之,我们展示了QAT在LLM中的首次应用,结果是首个准确的4位量化LLM。我们还展示了同时对权重、激活和KV缓存进行量化,这对于缓解长序列生成的吞吐量瓶颈至关重要。所有这一切都是通过一种新颖的无数据蒸馏方法(data-free distillation method)实现的,使得QAT在大型预训练生成模型中变得切实可行。
2 Method
使用量化感知训练(QAT)对大型语言模型(LLM)进行量化是一项复杂的任务,面临两个关键方面的挑战。首先,LLM经过预训练,以在零样本泛化中表现出色,保持这一能力在量化后至关重要。因此,选择合适的微调数据集非常重要。如果QAT数据在领域上过于狭窄或与原始预训练分布显著不同,这可能会损害模型性能。另一方面,由于LLM训练的规模和复杂性,很难完全复制原始训练设置。在第2.1节中,我们介绍了无数据量化感知训练(QAT),该方法使用下一个令牌数据生成QAT数据。与使用原始预训练数据的子集相比,这种方法表现出更优异的性能。其次,LLM具有独特的权重和激活分布,表现为显著的离群值,这使得它们不同于较小的模型。因此,适用于小模型的最先进的量化裁剪方法无法直接应用于LLM。在第2.2节中,我们确定了适合LLM的量化器(quantizers)。
2.1 Data-free Distillation
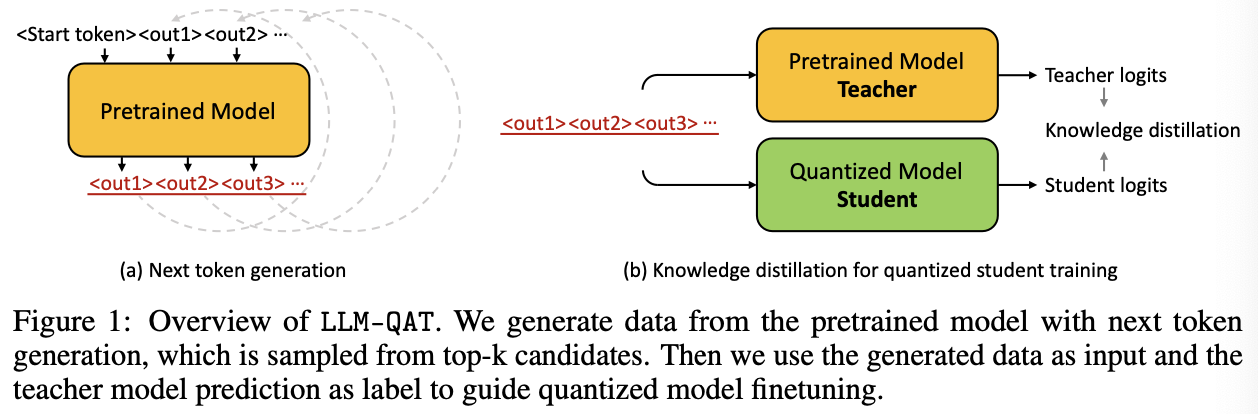
为了在有限的微调数据量下尽可能接近预训练数据的分布,我们提出了从原始预训练模型生成下一个令牌数据的方法。如图1(a)所示,我们从词汇表中随机选择第一个令牌<’start’>,并让预训练模型生成下一个令牌<’out1’>,然后将生成的令牌附加到开始令牌上以生成新的输出<’out2’>。我们重复这一迭代过程,直到我们达到句子结束令牌或最大生成长度。
我们在下一个令牌生成中测试了三种不同的采样策略。最直接的方法是选择前1名候选者作为下一个令牌。然而,这种生成的句子缺乏多样性,并且会周期性地重复几个令牌。为了解决这个问题,我们使用预训练模型的SoftMax输出作为概率,从分布中随机采样下一个令牌。这种采样策略生成了更多样化的句子,并大大提高了微调学生模型的准确性。此外,我们发现最初的几个令牌在确定预测趋势方面起着至关重要的作用。因此,这些令牌需要有较高的置信度。在我们的生成过程中,我们采用了一种混合采样策略,确定性地选择前3~5个令牌的顶级预测,然后随机采样剩余的令牌。在第3.3.1节中,我们对比了不同生成数据和真实数据的详细消融研究(ablation study)。
2.2 Quantization-Aware Training
2.2.1 Preliminaries
在这项工作中,我们研究了线性量化(linear quantization),即均匀量化(uniform quantization)。线性量化可以根据实值是否被裁剪分为两类:MinMax量化,它保留了所有的数值范围;以及基于裁剪的量化(clipping-based quantization)。
在MinMax量化中,量化过程可以表述如下:
其中,$X_Q$和$X_R$分别表示量化后变量和全精度变量。$i$表示张量中的第$i$个元素。$\alpha$表示放缩因子,$\beta$是零点值。对于对称量化:
对于非对称量化:
与MinMax量化相比,裁剪离群值可以帮助提高精度,并将更多的位分配给中间值。因此,许多近期的研究(Shen等,2020a;Zhang等,2020)采用基于裁剪的量化(clipping-based quantization)用于基于Transformer的语言模型。量化过程可以表述如下:
缩放因子$\alpha$和零点值$\beta$可以通过统计方法计算或通过梯度学习得到。
2.2.2 Quantization for Large Languare Models
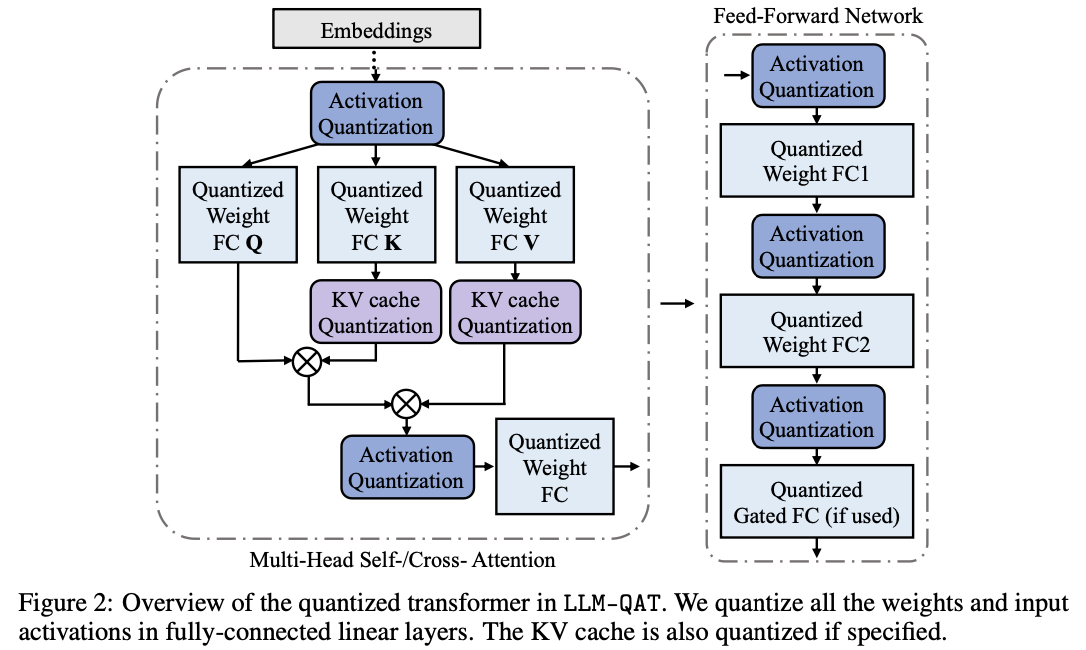
Quantization function
我们在图2中展示了量化后的Transformer模型。与(Dettmers等,2022;Xiao等,2022)的研究发现一致,我们也观察到了大型语言模型(LLM)的权重和激活中存在显著的离群值。这些离群值对量化过程有显著影响,因为它们会增加量化步长,同时降低中间值的精度。然而,在量化过程中裁剪这些离群值会对LLM性能造成不利影响。在训练的初期,任何基于裁剪的方法都会导致异常高的困惑度分数(即,> 10000),从而造成信息的大量丢失,难以通过微调恢复。因此,我们选择保留这些离群值。此外,我们发现,在带有门控线性单元(GLU)的模型中,激活值和权重大多呈对称分布。基于我们的分析和经验观察,我们选择对权重和激活值使用对称的MinMax量化:
这里,$(X_Q)$表示量化后的权重或激活值,$(X_R)$表示实值权重或激活值。为了确保高效的量化,我们采用如图3(a)所示的每个令牌激活量化和每个通道权重量化。对于不同量化器选择的全面评估,请参见第3.3.2节中的消融研究。
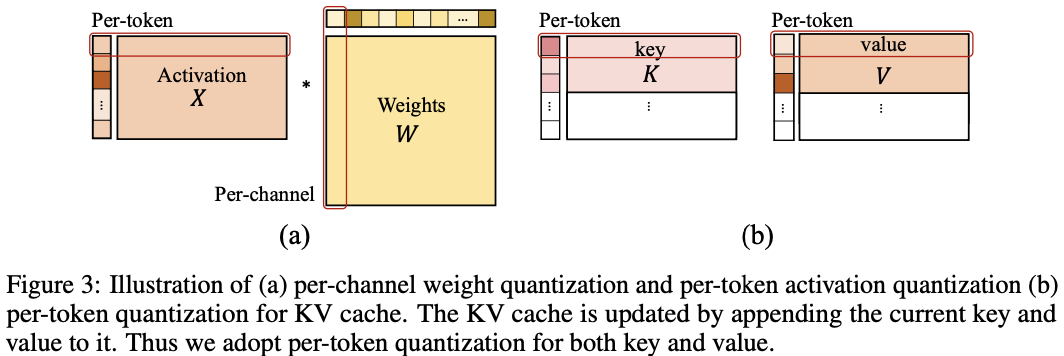
键值缓存的量化感知训练
除了权重和激活量化外,大型语言模型(LLM)中的键值缓存(KV缓存)也消耗了不可忽视的内存。然而,只有少数以往的工作关注了LLM中的KV缓存量化,这些方法主要限于训练后量化(Sheng等,2023)。在我们的研究中,我们展示了一种类似于激活量化的量化感知训练方法,可以用于量化KV缓存。如图3所示,由于键和值是逐个令牌生成的,我们在公式3中采用了每个令牌的量化。在生成过程中,当前的键和值被量化,并且它们的相应缩放因子被存储。在QAT的训练过程中,我们对键和值的整个激活张量应用量化,如图2所示。通过将量化函数整合到梯度计算中,我们确保了使用量化后的键值对进行有效的训练。
知识蒸馏
我们使用基于交叉熵的logits蒸馏方法,从全精度预训练教师网络 训练量化后的学生网络:
其中,$i$表示当前批次中的第$i$个样本,总共有$n$个句子。$c$表示类别数,在我们的情况下,它等于词汇表的大小。$\tau$和$S$分别是教师网络和学生网络。
正如第2.1节所讨论的,在数据生成过程中,从分布中采样下一个令牌比总是选择前1名候选者更为重要。通过这样做,下一个令牌不一定代表训练学生模型的最佳标签,因为采样引入了固有的噪声。因此,我们建议使用预训练模型的预测作为软标签,这为指导学生模型的训练提供了更具信息量的目标。我们在第3.3.3节中提出了详细的消融研究,以深入探讨这一方法的具体细节。
3 Experiments (表格数据看论文)
我们通过在LLaMA-7B/13B/30B模型上进行实验并在各种任务上展示结果来评估我们方法的有效性。具体而言,我们报告了在常识推理任务上的零样本性能,如BoolQ(Clark等,2019)、PIQA(Bisk等,2020)、SIQA(Sap等,2019)、HellaSwag(Zellers等,2019)、WinoGrande(Sakaguchi等,2021)、ARC(Clark等,2018)和OBQA(Mihaylov等,2018)。我们还评估了在TriviaQA(Joshi等,2017)和MMLU(Hendrycks等,2020)数据集上的少样本性能,以及在WikiText2(Merity等,2016)和C4(Raffel等,2020)数据集上的困惑度评分。
3.1 Experimental Settings
在我们的量化网络训练过程中,我们用预训练模型初始化模型,并将其用作知识蒸馏的教师模型。为了优化模型,我们使用AdamW(Loshchilov & Hutter, 2017)优化器,并设定权重衰减为零。每个GPU分配的批量大小为1,学习率设置为2e-5,采用余弦学习率衰减策略(cosine learning-rate decay strategy)。对于数据生成,我们使用LLaMA-7B模型,生成序列的最大长度设置为1024。
3.2 Main Results
我们考虑了三种训练后量化(PTQ)方法,分别是round-to-nearest(RTN)、GPT-Q(Frantar等,2022)和SmoothQuant(Xiao等,2022)作为基线。在不同的设置下比较它们,其中权重、激活值和KV缓存值被量化到不同的水平(表示为W-A-KV)。不同的PTQ方法在不同的设置下表现良好,我们将我们的方法与每个设置中最佳的PTQ结果进行比较。
表1、表2和附录中的表7分别给出了在常识推理任务的零样本任务、Wiki2和C4的困惑度评估以及MMLU和TriviaQA基准测试中的少样本精确匹配上,我们提出的QAT方法与SOTA PTQ方法的比较。困惑度评估验证了量化模型是否能够在其训练域的多样本上保留模型的输出分布。零样本和少样本评估衡量模型在下游任务中的能力是否得以保留。
每个表中的趋势类似。所有方法在8位设置下在所有模型大小中表现良好。这甚至在KV缓存与权重和激活值一起被量化到8位时也是如此。然而,当这些三个值中的任何一个被量化到低于8位时,PTQ方法会导致精度损失,而LLM-QAT表现得更好。例如,在8-8-4设置中,30B LLM-QAT实现了69.7的平均零样本准确率,而SmoothQuant为50.7(表1,第68-69行)。在4-8-8设置中,差异较小,但LLM-QAT仍比最佳的PTQ方法(在这种情况下为RTN)高1.4点(第55, 57行)。在4-8-4设置中,权重和KV缓存都被量化到4位时,所有PTQ方法产生的结果都较差,而LLM-QAT实现了69.9,仅比全精度模型低1.5点。LLM-QAT在6位激活量化中也表现得相当好。虽然由于缺乏硬件支持,这种设置目前可能不实用,但它是LLM子8位计算的一个有前景的数据点。不幸的是,4位激活量化在我们尝试的设置中效果不佳(见第3.4节)。
对从业者来说,一个重要的问题是是否使用全精度的小模型,还是使用具有类似推理成本的更大量化模型。虽然确切的权衡可能因几个因素而有所不同,但我们可以根据我们的结果提出几项建议。首先,8位量化应优于较小的全精度模型,对于这种情况,PTQ方法已足够。一个8-8-8 30B量化模型优于一个具有类似大小的13B模型,实际上应具有更低的延迟和更高的吞吐量。这同样适用于8位13B模型与16位7B模型的比较。此外,使用LLM-QAT量化的4位模型应优于具有类似大小的8位模型。例如,一个4-8-4 LLM-QAT 30B优于一个8位LLaMA-13B,而一个4-8-8 LLM-QAT 13B优于一个8位LLaMA-7B。因此,我们推荐4位LLM-QAT模型以获得最佳的效率-精度权衡。
3.3 Ablation
我们在第3.3.1节、第3.3.2节和第3.3.3节分别进行关于数据选择、量化方法和知识蒸馏方法的消融研究。我们报告了WikiText2(Merity等,2016)/C4(Raffel等,2020)数据集上的困惑度评分以及零样本常识推理任务的性能。
3.3.1 Data Choice
在表3中,我们观察到由维基百科文本构建的WikiText(Merity等,2016)并未涵盖预训练期间使用的所有信息。因此,仅在WikiText上微调的模型倾向于在该特定数据集上过拟合,并且难以很好地泛化到其他数据集。另一方面,Crawled Corpus(C4)数据集(Raffel等,2020)包括从网络收集的数百GB的干净英文文本。在C4上微调模型,在WikiText数据集上评估时获得了合理的迁移准确性。然而,当进行零样本推理任务时,其准确性表现较差。
与现有数据相比,在生成数据上微调的模型表现出更优越的泛化能力,特别是在零样本任务中。此外,通过从分布中采样生成的数据相比不采样生成的数据展示出更大的多样性。这种增强的多样性在所有任务中显著提高了性能。
3.3.2 Quantization Function
我们在表4中比较了无裁剪量化方法与基于裁剪的方法。按照之前工作的实践(Liu等,2022b,2023),我们使用StatsQ(Liu等,2022a),这是一个统计计算的缩放因子用于基于裁剪的权重量化,以及LSQ(Esser等,2019),一个用于基于裁剪的激活量化的可学习缩放因子。然而,我们的发现表明,这两种最先进的基于裁剪的量化方法并未超越MinMax非裁剪方法所取得的性能。这一观察结果加强了保留离群值对大型语言模型性能至关重要的论点。
此外,我们观察到对于LLaMA模型,激活值和权重主要表现出对称分布,这使得使用对称量化器成为最佳选择。然而,重要的是要注意,这一结论可能不适用于其他大型语言模型,特别是那些包含GeLU层的模型。
3.3.3 Knoledge Distillation
表5显示,不同的知识蒸馏方法对微调模型的最终准确性有显著影响。值得注意的是,仅使用下一个令牌作为标签是次优的,因为在生成过程中从候选分布中采样引入了固有的随机性和噪声。相比之下,使用教师模型的完整logit分布预测的logit蒸馏,比基于标签的训练方法导致微调模型的性能更优。有趣的是,我们观察到,加入注意力蒸馏或隐藏层蒸馏实际上会降低性能。因此,我们在所有实验中都仅使用logit蒸馏。
3.4 Compatibility with SmoothQuant
我们的方法也兼容SmoothQuant(Xiao等,2022)提出的权重激活重缩放技术。表6显示,将SmoothQuant整合到4位权重4位激活(W4A4)量化中可以进一步提高准确性。然而,在激活位数大于权重位数的情况下(即W4A8),添加SmoothQuant并不会带来任何改进,甚至可能会损害性能。
4 Related Works
量化
神经网络量化已被证明是压缩模型大小和减少存储消耗的有效工具。经典的量化方法,如MinMax量化(Jacob等,2018;Krishnamoorthi,2018)、学习步长量化(Esser等,2019)、PACT(Choi等,2018)、N2UQ(Liu等,2022a)等,主要是为卷积神经网络开发的。虽然一些近期工作探索了语言模型的压缩,但它们主要集中在较小的模型上(Zafrir等,2019;Fan等,2020;Shen等,2020b;Zadeh等,2020;Bai等,2021;Qin等,2021;Liu等,2022b),如BERT(Devlin等,2019)或BART(Lewis等,2019)。对于大型语言模型(LLM),现有的量化方法主要限于训练后量化(Xiao等,2022;Yao等,2022;Frantar等,2022),这是由于缺乏可获得的训练数据或在整个预训练数据集上微调所需的资源过于庞大。据我们所知,之前的工作中没有研究LLM的量化感知训练的具体挑战。
数据生成
QAT的数据生成仍然是一个相对未被充分研究的领域。尽管在视觉领域有一些工作使用预训练教师模型生成的数据微调学生网络(Yin等,2020;Liu等,2022c;Cai等,2020),这些方法主要集中在图像数据上。它们涉及基于从标签计算的梯度更新噪声输入,并通过累积这些梯度重建图像。相比之下,我们提出的方法引入了语言领域的下一个令牌数据生成。这种方法更自然,并证明对微调量化语言模型有效。
5 Conclusion and Limitations
我们提出了无需数据的量化感知训练(QAT)方法用于大型语言模型(LLM),并展示了使用该技术可以实现精确的4位量化。鉴于这种对训练数据无关的蒸馏方法的普遍性以及LLM部署成本的不断增加,我们预计该方法将具有广泛的适用性。例如,该方法也可以用于在多个阶段训练的模型,如指令调优或强化学习(Ouyang等,2022)。我们将这一研究留待未来工作进行。由于4位量化没有现成的硬件支持,我们没有将硬件实现包含在本工作中。然而,我们正在与合作伙伴合作,以在不久的将来实现这一点。虽然我们的方法在4位权重、4位KV缓存和8位激活量化方面表现良好,但对于4位激活量化来说仍然不够充分,这一情况需要进一步研究。
重点和创新
这篇论文是对large language model LLM的量化研究。使用的QAT quantization-aware training量化感知训练方法。具体的,提出了一种无数据蒸馏方法(data-free distillation method),该方法通过使用LLM自身生成的数据进行知识蒸馏,可以适用于任何模型。
并且除了量化权重和激活值之外,还量化了KV缓存。在LLaMA模型上进行了实验,量化最低达4位,还实现了6位量化。
为什么提出无数据蒸馏方法,因为对LLM进行QAT量化感知训练有几个难点:
其一,对LLM选择合适的微调数据很重要。如果微调数据与原始预训练数据的分布不符合,或者微调数据过于狭窄,会导致微调反而损害模型性能;
其二,由于LLM预训练的复杂性和规模之大,我们很难完全复制原始的训练设置;
其三,LLM有独特的权重和激活分布,它们不同于小型模型,因此适用于小模型的量化裁剪方法可能不适用于LLM。
基于这几个难点,本论文提出了无数据的蒸馏方法:
该方法使用原始预训练模型生成下一个token数据,以此得到QAT数据。使用混合采样,对最开始的3~5个token采用top预测采样,对后面的token采用基于输出概率的随机采样。(具体看2.1节)
量化方程:
线性量化分为MinMax量化和基于裁剪的量化,MinMax量化又分为对称量化和非对称量化。
本论文对权重和激活值使用对称的MinMax量化,之所以没有用裁剪量化,是因为LLM的权重和激活值中存在显著的离群值,裁剪这些离群值会对模型性能造成不利影响。在训练初期,任何基于裁剪的方法都会导致大量信息丢失,因此我们保留这些离群值。
此外对KVcache的量化,也使用公式3的MinMax对称量化,当前key和value被量化,相应的缩放因子被存储。
预备知识
关于LLM量化的基础知识:
“大模型量化技术的原理和代码实现”
什么是老师学生模型:
什么是知识蒸馏:
参考
论文:LLM-QAT: Data-Free Quantization Aware Training for Large Language Models