GPT2模型原理的通俗理解
本文最后更新于 2024年7月10日晚上6点08分
GPT2模型原理的通俗理解
GPT2和只带有解码器decoder的transformer模型很像. 它有超大规模,是一个在海量数据集上基于transformer解码器训练的模型. BERT模型则是通过transformer编码器模块构建的.
通俗而言,gpt2就是根据现有句子,预测下一个单词会是什么. 它像传统的语言模型一样, 一次只输出一个单词token, 每次产生新单词后,该单词会被添加在之前生成的单词序列之后, 这个序列会成为模型下一步的新输入. 这种机制叫做自回归(auto-regression), 也是令RNN效果超群的重要思想. BERT没有使用自回归机制, BERT获得了结合单词前后的上下文信息的能力, 也能取得很好的效果.
浅析内部结构
下面看GPT2的内部结构, 它是如何工作的:
GPT-2最长可以处理1024个token的序列,每个token都会和它的前续路径一起‘流过’所有的decoder模块.
假设现在gpt2已经训练好了, 只需要提供一个预先定义好的起始单词(训练好的模型会使用endoftext作为起始单词,不妨称其为s), 然后让它自己生成文字.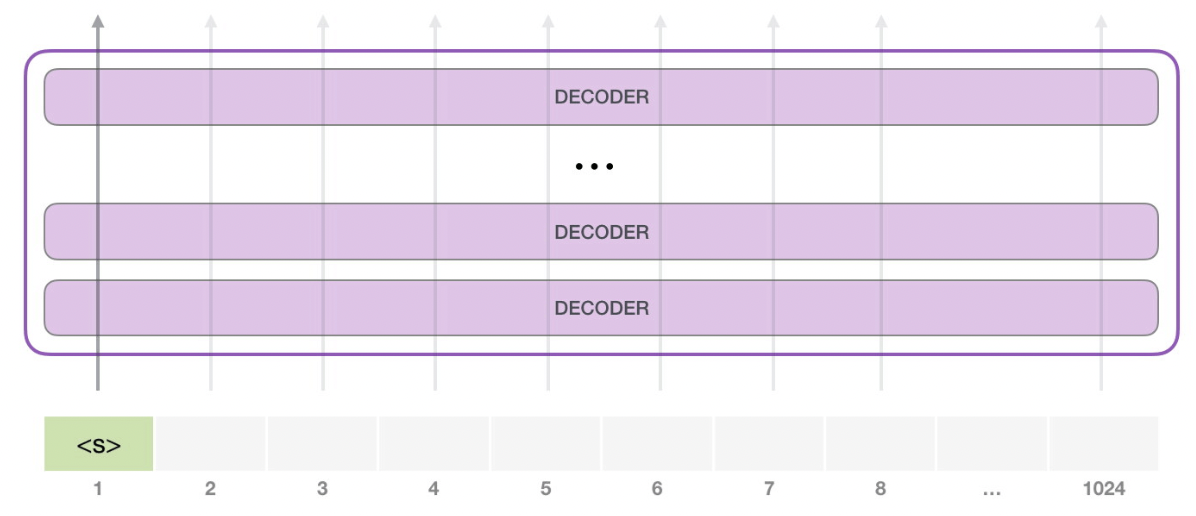
此时, 模型的输入只有一个单词, 经过层层处理, 最终得到一个输出向量. 向量对词汇表中每个单词计算一个概率, 选择概率最高的单词作为输出单词, 假设‘The’作为输出.
但这样有一个问题: 它可能会陷入推荐同一个单词的循环中, 比如一直重复输出概率最高的单词‘The’, 只有选择概率第2或者第3的单词才能跳出这个循环. 所以, gpt2会有一个叫做‘top-k’的参数, 模型从概率前k的单词中随机抽取下一个单词.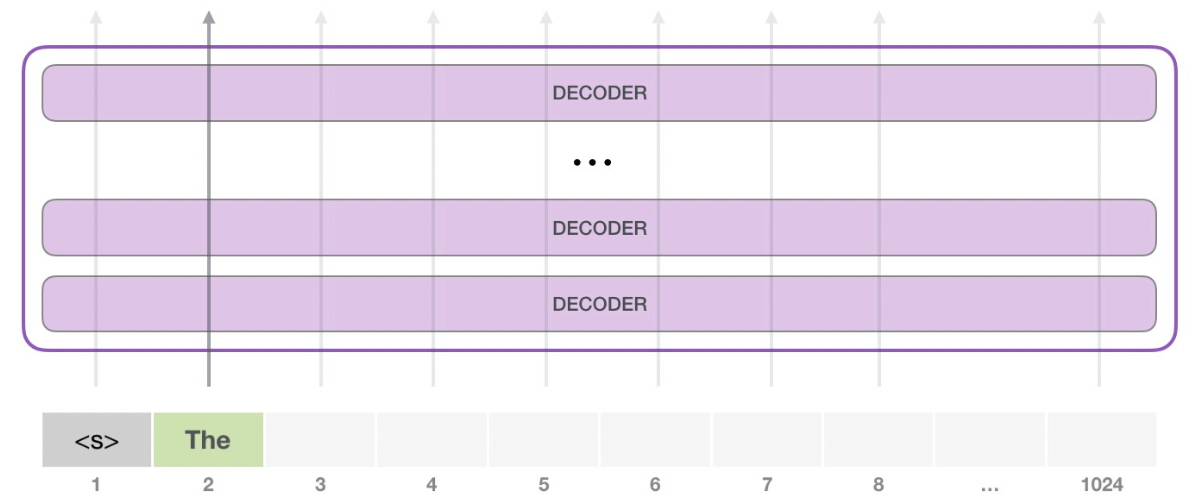
深入理解内部原理
嵌入矩阵和位置编码
模型首先输入一个句子, 句子先tokenizer分词(以subword为基本离散单位)为一个个子词subword, 每个子词用词表中的index表示, 词表大小为50257.
然后通过嵌入矩阵, 找到每个子词对应的词向量. 嵌入矩阵的行数=词表长度50257, 嵌入矩阵的列数=embedding size, 即每个子词对应的词向量的长度. 最小的gpt-small模型会有1*768的长度表示一个子词.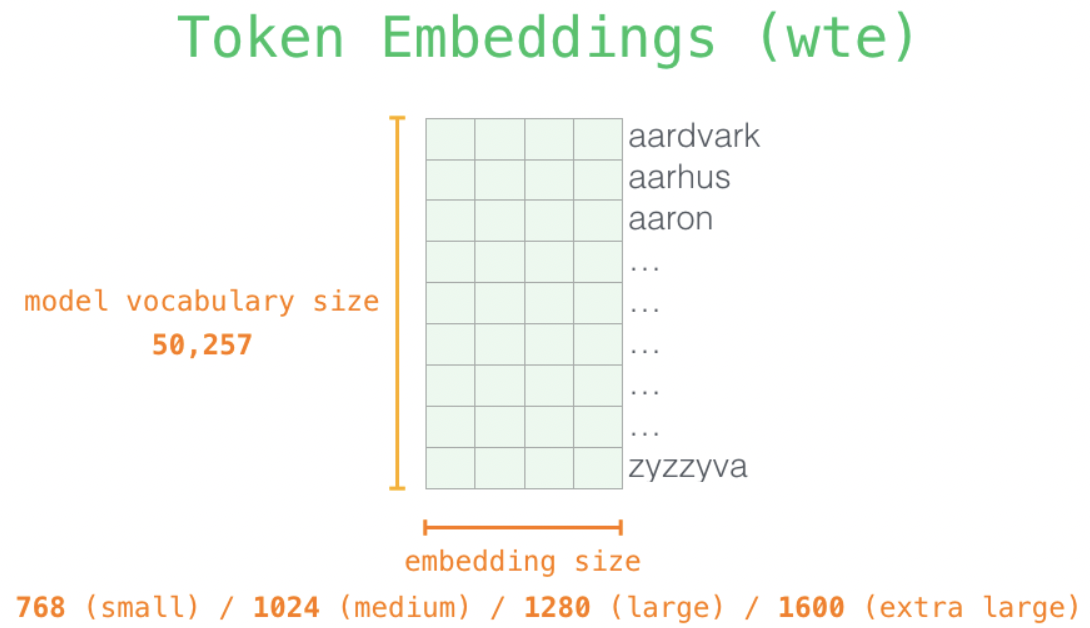
嵌入矩阵的每一行都是一个词嵌入向量. 最开始, 需要从嵌入矩阵中找到起始单词s对应的词向量. 然后引入位置编码, 位置编码矩阵如下, 行数表示输入的context的长度(即一个句子分解为子词的个数), 列数同样为embedding size: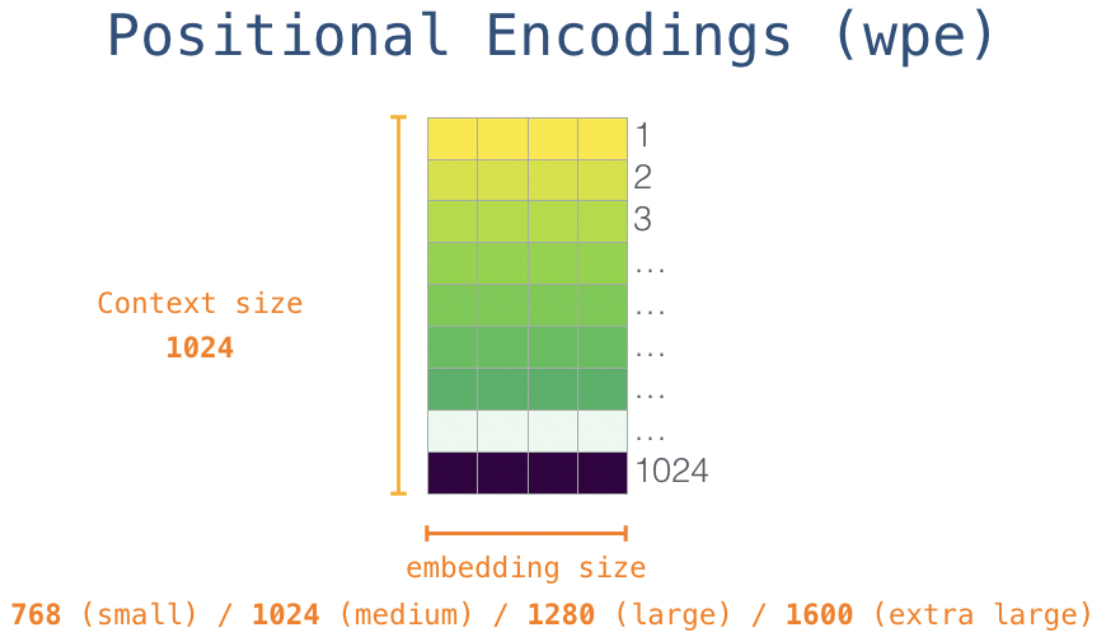
输入的单词经过嵌入矩阵和位置编码后, 进入transformer之前的步骤就完成了. 然后经过第一个transformer-decoder模块:
首先是自注意力层 masked self-attention, 然后传输给feed forward neural network. 第一个decoder模块完成后, 会把结果向量传给第二个decoder模块, 每个decoder模块的处理方式都是一样的, 但每个模块会维护自己的自注意力层和feed forward层的权重.
自注意力机制
从之前的attention帖子详细理解attention的原理, 我们了解到自注意力机制的公式:
自注意力机制就是: 对序列中每个单词, 都赋予一个相关度得分$softmax(\frac{QK^T}{\sqrt{d_k}})$, 然后对他们的向量表征$V$乘以这个相关度得分, 即对向量表征加权求和, 所加的这个权重是相关度得分.
自注意力机制中的Query, Key和Value的含义:
- Query查询向量: 当前单词的查询向量被用来和其它单词的键向量相乘,从而得到其它词相对于当前词的注意力得分。只关心目前正在处理的单词的查询向量。
- Key键向量: 键向量就像是序列中每个单词的标签,它使搜索相关单词时用来匹配的对象。
- Value值向量: 值向量是单词真正的表征,当算出注意力得分后,使用值向量进行加权求和得到能代表当前位置上下文的向量。
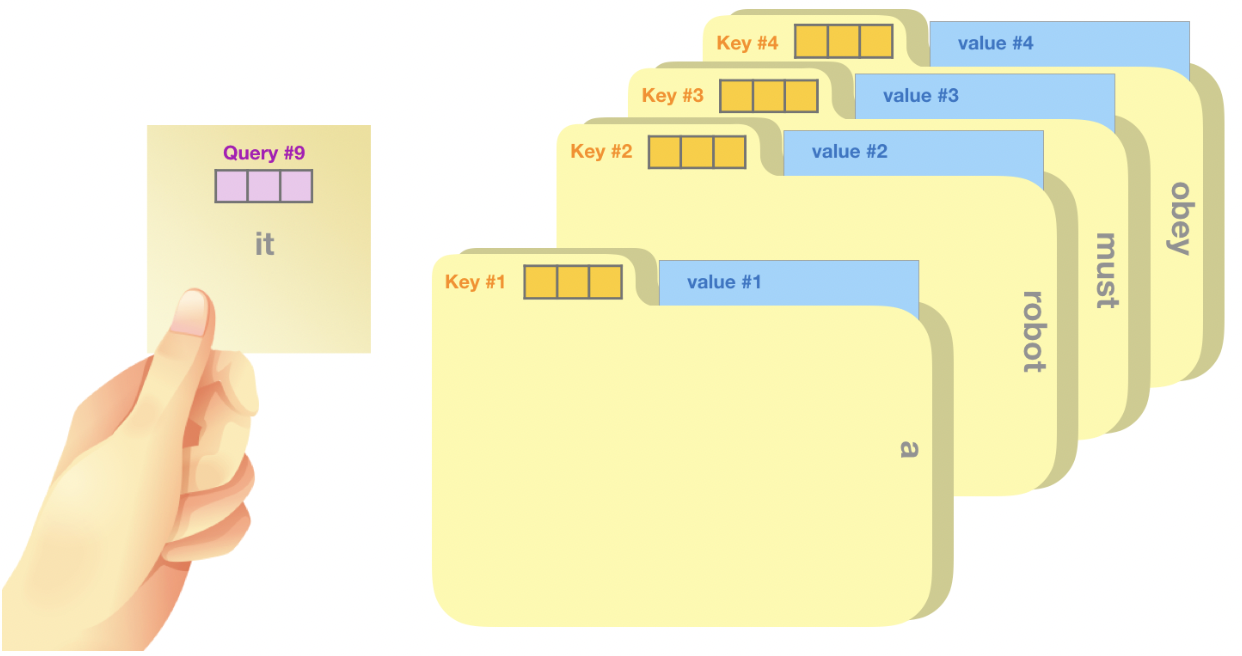
一个简单粗暴的比喻是在档案柜中找文件。查询向量就像一张便利贴,上面写着你正在研究的课题。键向量像是档案柜中文件夹上贴的标签。当你找到和便利贴上所写相匹配的文件夹时,拿出它,文件夹里的东西便是值向量。
将单词的查询向量分别乘以每个文件夹的键向量,得到各个文件夹对应的注意力得分(这里的乘指的是向量点乘,乘积会通过 softmax 函数处理)。
将每个文件夹的值向量乘以其对应的注意力得分,然后求和,得到最终自注意力层的输出。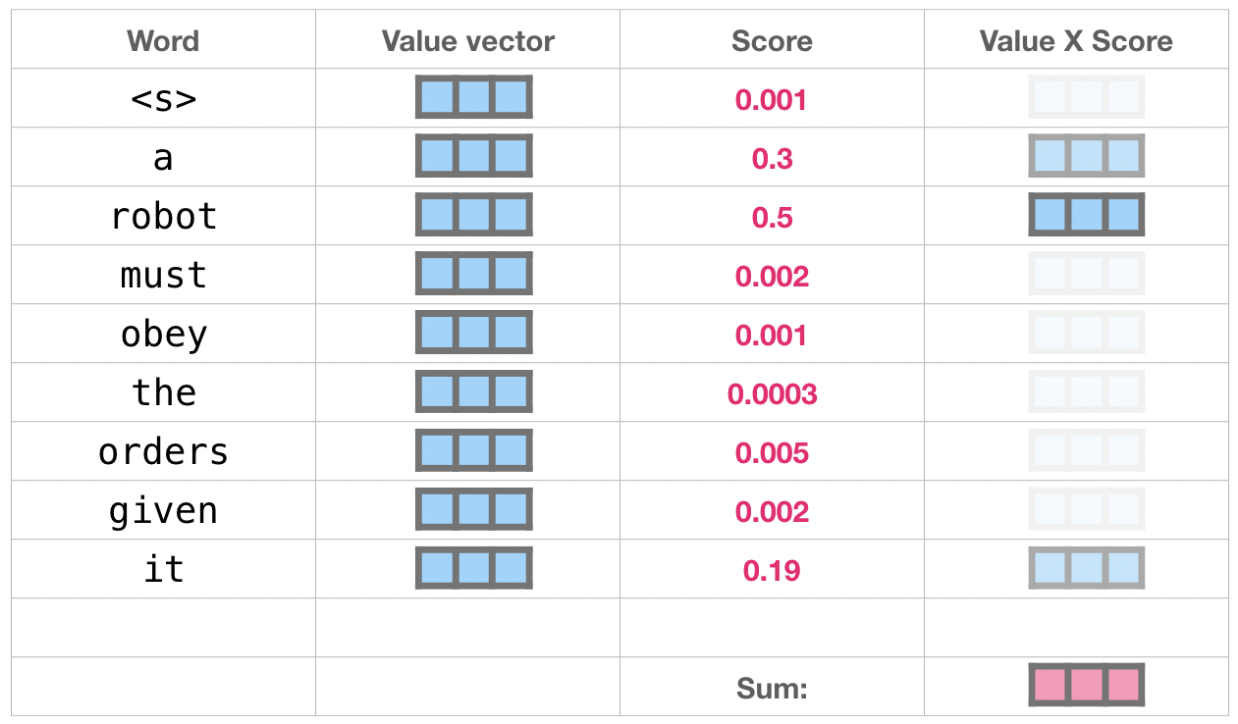
模型输出
向量经过自注意力机制和feed forward层后,得到输出向量, 这个向量和嵌入矩阵相乘, 得到词汇表中每个单词的注意力得分. 因为嵌入矩阵$M$大小为$50257 \times 768$, 输出向量$X$的大小: $1\times 768$, $size (M \times X^T) = 50257 \times 1$.
选取得分最高的单词为输出结果(top-k=1时). 但更好的策略是选择得分较高的一部分单词,将他们的得分作为概率从整个单词表中抽样(得分高的单词更容易选中). 一般的, top-k=40.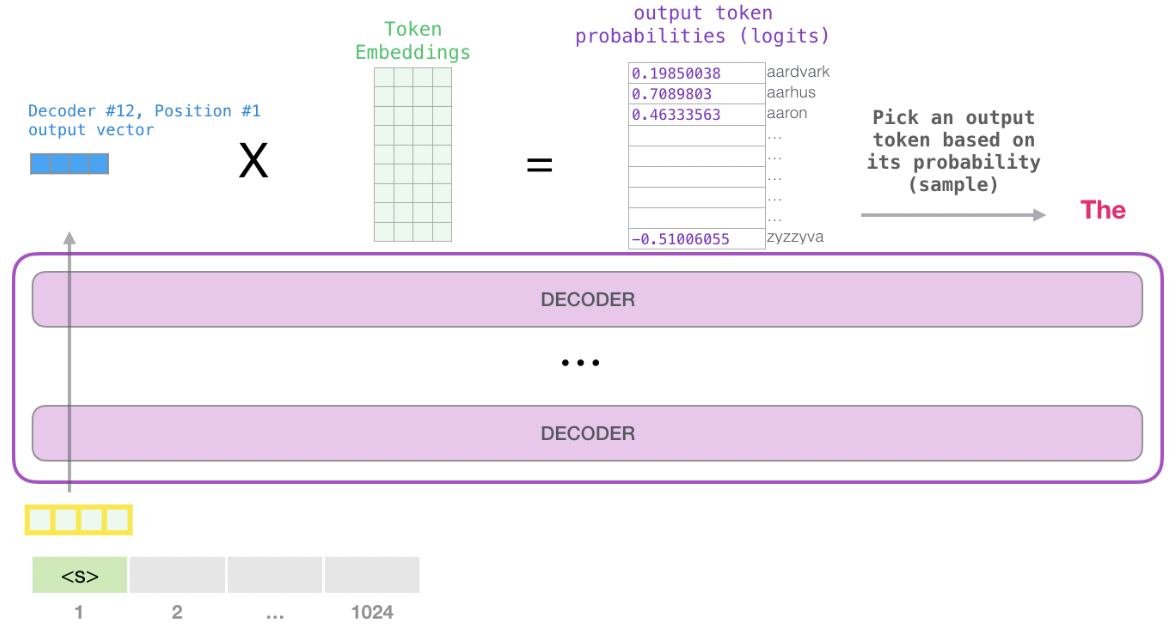
以上, 模型完成了一次迭代. 模型不断迭代直到生成一个完成序列, 序列得到1024或者生成终止符.
其他
BERT模型的原理结构
代码中的gpt2
参考
中文博客园: GPT-2通俗理解
Jay Alammar博客: The Illustrated Transformer