HMA论文-存内计算方向
本文最后更新于 2024年7月11日下午1点37分
HMA论文
今天我们看这篇论文: Heterogeneous Memory Architecture Accommodating Processing-In-Memory on SoC For AIoT Applications. 链接: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9712544
Abstract
由于其低计算延迟、大吞吐量和高能效等吸引人的特点,存内计算(PIM)技术是人工智能物联网(AIoT)应用最有前途的候选技术之一。然而,如何高效地将PIM与片上系统(SoC)架构结合使用却很少被讨论。在本文中,我们展示了一系列从硬件架构到算法的解决方案,以最大化PIM设计的优势。首先,我们提出了一种异构内存架构(HMA),通过高吞吐量的片上总线将现有SoC与PIM连接起来。然后,基于给定的HMA结构,我们还提出了一种HMA张量映射方法,用于划分张量并在PIM结构上部署通用矩阵乘法操作。HMA硬件和HMA张量映射方法都利用了成熟嵌入式CPU解决方案堆栈的可编程性,并最大化PIM技术的高效性。与最新的加速器解决方案相比,整个HMA系统可以节省416倍的功耗以及44.6%的设计面积。评估还表明,与最新基线和未经优化的PIM相比,我们的设计可以分别将TinyML应用的操作延迟减少430倍和11倍。
关键词—内存中处理,内存中计算,片上系统,可编程架构,硬件/软件接口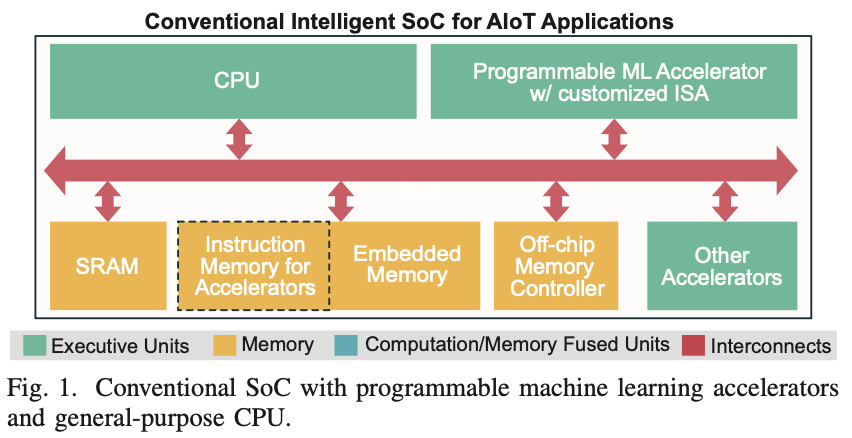
1 Introduction
人工智能和物联网(AIoT)的结合催生了各种特定领域的加速器,以实现低功耗的设备端智能[1]。AIoT设备在传感器附近进行本地数据分析,通常在10mW以下的电池或能量收集电源下运行。因此,AIoT技术需要包含通用CPU和可编程机器学习(ML)加速器的低成本小型片上系统(SoC),以兼顾可编程性和执行效率(图1)。本文旨在通过内存中处理(PIM)技术来增强这些嵌入式SoC,处理大量的通用矩阵乘法(GEMM)操作。
PIM设计旨在直接在内存阵列中进行计算操作。不同计算接口电路的PIM设计已经被展示[2], [3], [4], [5], [6]。此外,程序化架构也被探索过[7], [8], [9]。尽管在电路级别的PIM设计已经得到了很好的探索,如何将PIM接口引入SoC仍然不清晰。在上述最先进的PIM硬件设计中,PIM被视为一个变异的向量处理单元,形成加速器,即PIM与定制指令集架构(ISA)集成[7], [10]。然而,在SoC级别,由于需要额外的定制指令和与主处理器共享内存的分配,这种架构可能效率不高,导致编译问题复杂。因此,大多数情况下很难达到峰值效率。
为了解决这个问题,我们提出了一种异构内存架构(HMA),以适应现成的嵌入式SoC架构中的PIM。“异构内存”的概念在此被提出,表示这种架构在一个SoC上既包含PIM内存,也包含传统内存(只能存储和读取数据的内存)。在提出的HMA中,PIM内存与传统内存一样连接到片上的高吞吐量系统总线。HMA极大地简化了程序接口,我们还开发了HMA张量映射方法,作为将GEMM部署到提议架构的软硬件优化。
本文的主要贡献包括:
- 我们提出了一种新颖的异构内存概念和架构,以PIM内存扩展内存空间。据我们所知,提出的HMA方案是第一个明确说明如何将PIM接口引入现成SoC的架构。
- 我们设计了HMA张量映射方法来划分张量并将GEMM任务部署到提议的硬件架构中。这种方法不仅为程序员提供了一种与硬件无关的方式来利用PIM硬件,还可以用作预设计规范估计。
- 我们创建了一个软硬件开发流程,使PIM能够使用现成的gcc编译器,弥合了硬件和软件工具链之间的差距,以在SoC中开发PIM。
本文重点介绍了利用嵌入式非易失性存储技术制造的PIM,以利用其零待机功耗特性。我们对提出的HMA的评估基于电阻式随机存取存储器(RRAM)。
本文其余部分组织如下:第二节介绍PIM的背景。我们在第三节和第四节介绍了提出的架构和算法。评估结果在第五节展示,第六节对本文进行了总结。
2 Preliminaries
2.A ASIC Accelerators in SoC
图1显示了在SoC中将应用专用集成电路(ASIC)加速器接口的现有方案。ASIC加速器是为特定任务设计的,具有应用特定的优化硬件实现。ASIC加速器或协处理器通常与主处理器并行工作,并与它们共享总线和内存。完全定制的ISA或扩展到公共标准(例如RISC-V)的ISA用作软硬件程序接口。存储指令的内存(“指令内存”)通常通过连接到系统总线从外部加载到加速器。在这样的SoC中,片上总线(例如AXI, AHB等[11])不仅负责数据通信,还传输加速器执行的指令。这种内存共享和在同一总线上混合传输加速器指令的模式使得编译和调度变得非常复杂,进而引发设计工作量和开销。
2.B Processing-In-Memory
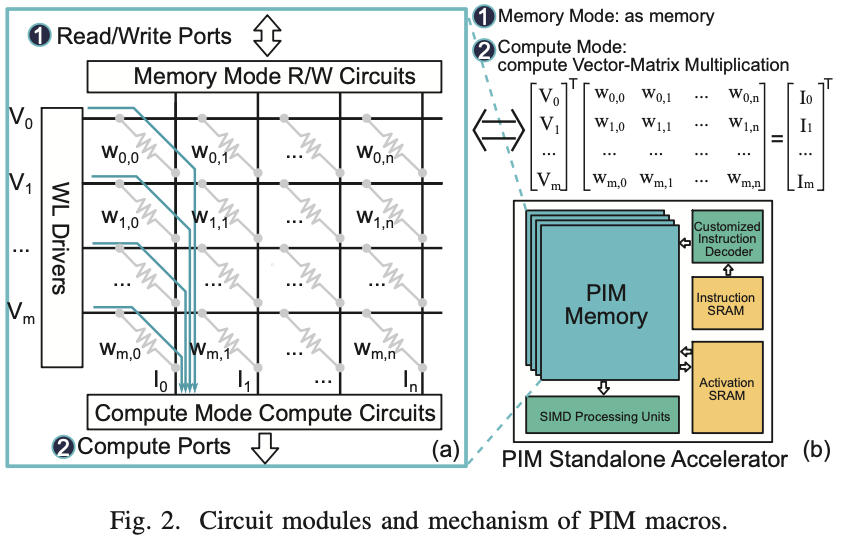
PIM技术通过添加计算接口电路对内存电路进行了改造。如图2所示,PIM有两种工作模式:内存模式和计算模式。在内存模式下,可以通过读/写端口访问数据,从内存阵列中读取或写入数据;而在计算模式下,向量形式的输入数据“V”流入PIM内存。这些输入数据直接与存储在PIM内存单元中的数据交互【2】,输出结果可以锁存在输出端口“I”。PIM内存以模拟处理的方式计算GEMM,通过模数转换器(ADC)作为计算电路接口:I = VW,其中V是流入的输入,W是存储在PIM内存中的数据,I是计算结果。
将PIM内存阵列与指令解码器和数据路径控制器一起排列形成PIM加速器。最先进的PIM加速器根据PIM的新型编程模型定制指令【12】。然而,将软件程序编译和部署到PIM硬件上是一个非常复杂的问题【13】【14】,目前仍在研究和开发中。
2.C GEMM optimization
PIM架构可用于大多数AIoT应用,特别是机器学习(ML)和深度神经网络(DNN)。大规模矩阵乘法占总体操作的70%以上【15】,PIM硬件可以大大减少计算时间。在算法层面,矩阵乘法的时间复杂度可以通过Strassen算法和Winograd算法来降低【16】。在微架构层面,优化措施包括改善内存访问局部性和使用向量指令,以减少内存访问时间并提高缓存命中率。在本文中,我们采用硬件/软件协同设计方法,在PIM技术的帮助下加速GEMM。
3 Heterogeneous Memory Architecture
为了解决上述挑战,我们提出了异构内存架构(HMA),这是一种简约的设计,通过引入PIM内存来升级现有SoC设计,从而提升性能和效率。
3.A Overall Structure
HMA的核心思想是将PIM内存以与传统内存相同的方式附加在SoC上,而不是像图2(b)所示那样构建独立的PIM内存加速器。图3展示了HMA结构在SoC上的整体工作原理。图2(a)展示了PIM内存中的硬件组件。PIM输入/输出缓冲区(通过静态随机存取存储器(SRAM)实现的片上高速内存,用于缓存PIM计算的输入/输出数据)和PIM内存通过互连接口安装在系统总线上。计算模式下的输入通过物理金属总线连接,使PIM内存可以直接访问PIM输入缓冲区中的数据。输出数据锁存器,加上额外的多路复用器/解码器和总线从属模块,形成了一个“虚拟输出缓冲区”,即通过系统总线可以寻址的输出数据块。额外的PIM输出缓冲区是完成GEMM操作所必需的,用于缓存中间部分和的结果。在这种硬件结构下,CPU指示PIM进行编程并执行内存中的GEMM计算。HMA的详细编程模型在第四节中描述。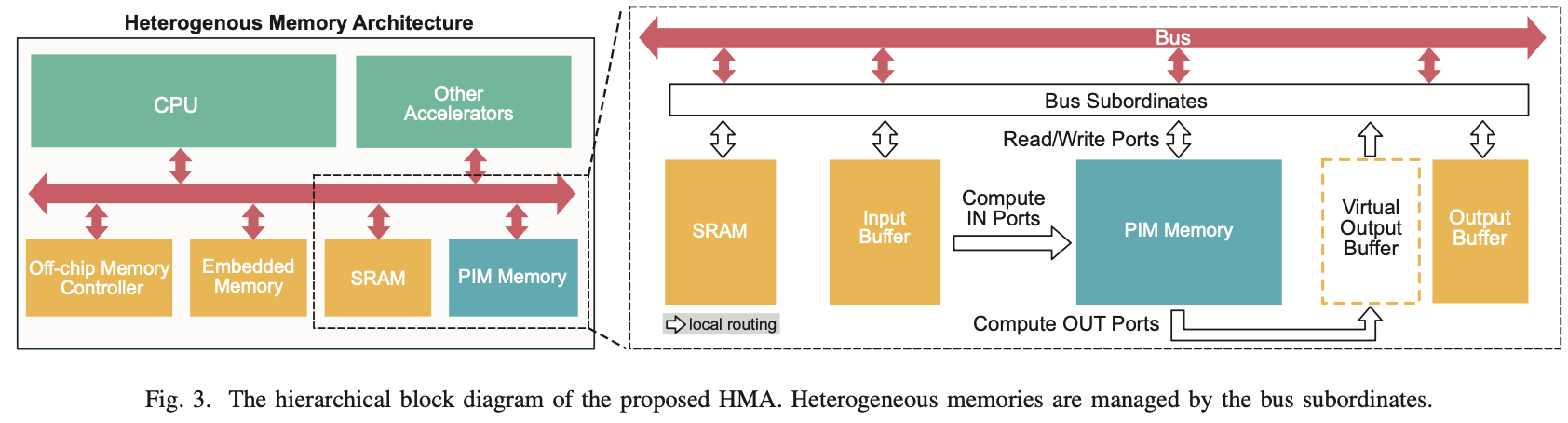
图4展示了HMA内部地址分配的一个典型案例。整个地址空间可以分为几个块。我们以一个小型AIoT SoC设计为例。总地址宽度设为32位。每64MB组成一个块。块0和块7中的地址保留用于CPU配置、指令存储、内部外围设备等。块1覆盖片上SRAM和连接到低速总线的外部外围设备。PIM相关的缓冲区和PIM内存独占块3用于GEMM加速。在这个例子中,剩余的块4至6可用于未来扩展。请注意,不同形式的SoC可能根据其独特的总地址宽度和片上内存及PIM内存的规模,导致不同的分块方法。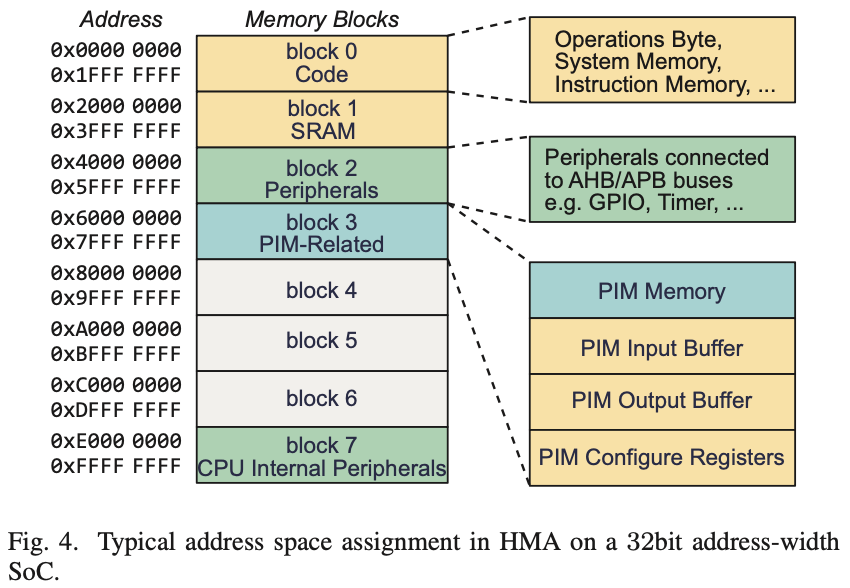
3.B Data Transportation
HMA实现的一个关键前提是片上互连网络能够提供足够的带宽来支持与PIM相关的双向数据传输,即:(a) 情况A:从PIM输出缓冲区获取PIM计算结果;(b) 情况B:将输入向量/矩阵传输到PIM输入缓冲区。我们通过模拟AHB通信来验证这一点。寄存器传输级(RTL)代码在28nm工艺节点下进行综合和仿真,片上时钟为1GHz,总线宽度为128位。PIM相关信息汇总在表1【3】。
结果如图5所示。Y轴是数据传输率。顶部X轴是突发增量模式下AHB总线的事务大小,底部X轴是PIM内存阵列的数量。我们模拟这种模式是因为向量/矩阵中的元素大多与线性分布的地址对齐。如表1所示,每个PIM内存阵列的大小为256kb。多个PIM内存阵列并行工作,使得输入/输出数据传输率线性增加。
图5(a)和(b)分别展示了两种情况的结果。它们分别对应于AHB管理器的读操作(情况A)和写操作(情况B)。结果表明,同时工作的PIM内存阵列越多,总线所需的数据传输率就越高。事务大小应提高到64字节,以涵盖高达3000MB/s的8个PIM内存阵列的高PIM输出吞吐量。通过这种方式,常用的AHB可以处理PIM的输入和输出,而不会出现额外的拥塞或互连缓冲。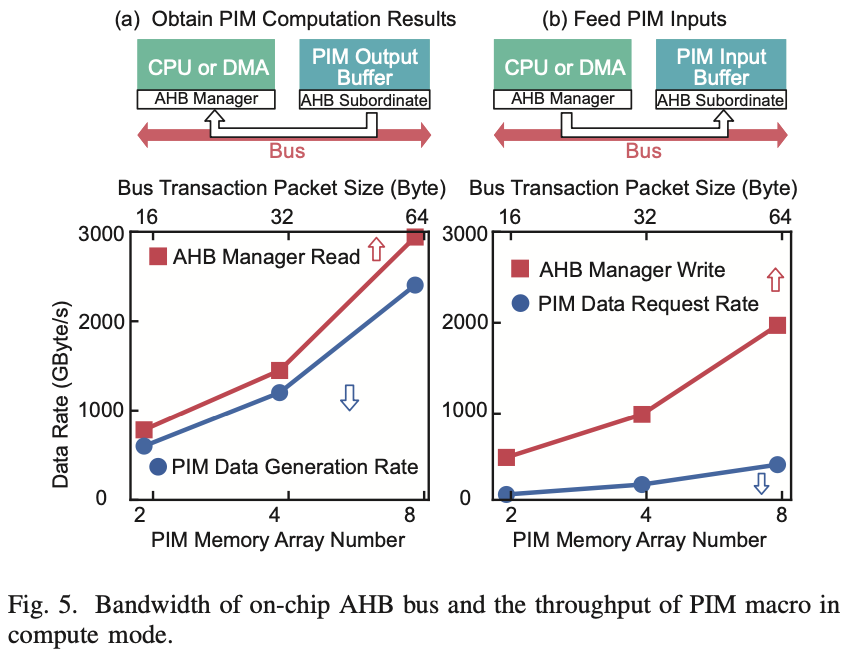
4 HMA Tensor Mapping Approach
基于HMA硬件基础设施,我们提出了一种软硬件协同设计方法,即HMA张量映射方法,以提高计算效率并最大化HMA结构的优势。
4.A Approch Background
如前所述,深度神经网络需要进行大量高维矩阵运算,这些运算全部发生在我们的设计中的PIM内存中。在大多数情况下,操作数矩阵的大小大于单个PIM内存提供的单元大小。更具体地说,第五节中的示例性PIM内存在维度为I的情况下执行I = VW,其中I为1×16,V为1×64,W为64×16。而经典的简单两层感知器涉及一个784×100的权重矩阵,远大于64×16【17】。因此,存储在传统内存中的所有相关高维和大规模输入数据以及权重数据都需要进行分区并输入到PIM内存中以提高计算效率。
基于我们的方法,我们将PIM内存中的所有矩阵乘法直接编译为一系列普通的内存操作指令,相比之下,传统的PIM加速器将PIM中的GEMM归因于定制指令控制【10】。通过这一创新,PIM计算可以通过gcc工具链轻松编译,并基于这些指令在软件中进行优化。
表II中给出了PIM指令的内存版本的详细解释。指令中的(x,y)表示传统内存中矩阵左上角元素的地址偏移。
4.B Optimization Method of HMA-GEMM Execution
对于大多数设计而言,可以使用多个PIM和HMA结构来增强系统性能。这些PIM内存应并行调度,以利用神经网络计算中PIM内存中的权重数据不需要频繁更改的事实。因此,如何分解这些操作取决于可访问的HMA架构数量。如果PIM内存数量足够多,可以覆盖整个矩阵权重,则权重数据可以保持不分割并部署在每个PIM内存中。然而,在大多数实际情况下,PIM和HMA结构不足以直接覆盖神经网络计算中的矩阵权重。由于这种硬件限制,权重数据无法在这些PIM中保持不变。与传统GEMM频繁交换权重数据不同,我们将操作拆分为多组乘法和加法。每个输入数据与已经存储在PIM矩阵中的某个权重相关联,需要一起计算,这样可以减少PIM内存中权重数据重新加载的频率。加载到同一行不同PIM输出缓冲区的计算结果相应叠加。当所有乘法结果准备就绪后,接下来进行加法操作。在最后一步,不同列的加法结果将横向拼接完成一次GEMM操作。
图6展示了优化前后的GEMM伪代码以及HMA张量映射方法的图模型。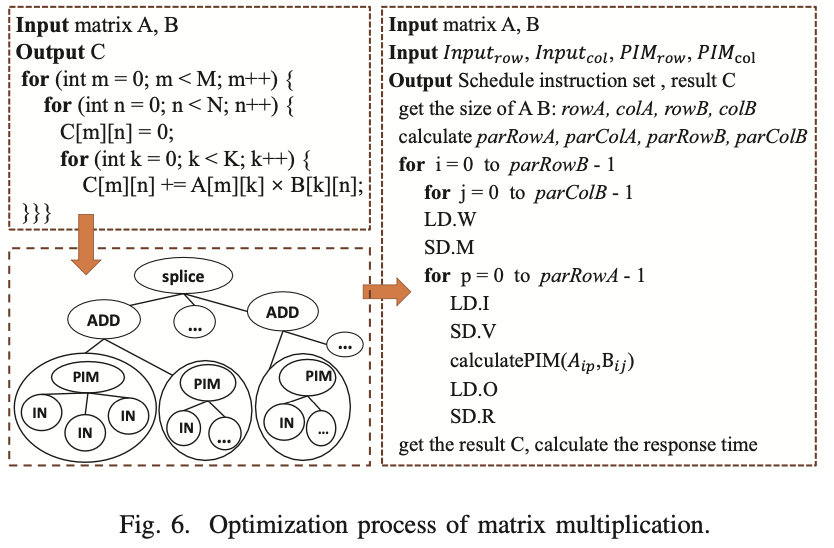
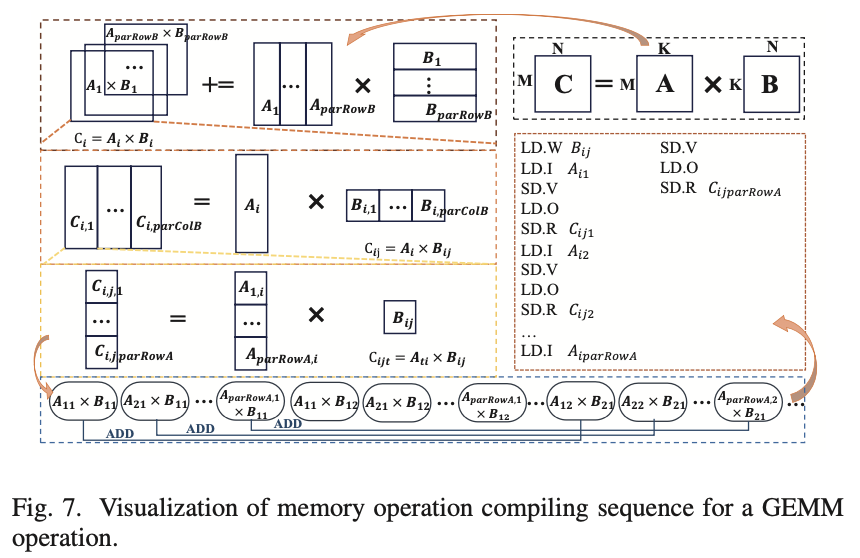
例如,在PIM结构中计算矩阵乘法C = A × B,其中操作数矩阵A和B的大小分别为100×400和400×80。PIM输入的大小为1×64,每次操作PIM内存的GEMM大小为64×16。为了简单起见,我们假设只有一个HMA结构。此操作可以通过HMA-PIM按以下步骤完成(如图7所示):
- “LD.W (0,0)”和“SD.M”:从B矩阵的(0,0)位置获取数据并将其存储在HMA的PIM内存中;
- “LD.I (0,0)”和“SD.V”:从A矩阵的(0,0)位置获取数据并将其存储在HMA的输入缓冲区中;
- “LD.O”和“SD.R (0,0)”:从输出缓冲区获取结果并将其存储在传统内存中;
- “LD.I (1,0);…;LD.I (99,0)”:重复此过程依次从A矩阵中取出数据,在PIM中计算;
- “SD.R (1,0);…;SD.R (99,0)”:写回PIM的计算结果;
- “LD.W (0,16)”:更新PIM内存中的数据并重复步骤1-5。
4.C Memory Access Frequency
频繁的内存访问会导致额外的开销,因此我们希望通过PIM来减少这种开销。本小节中将分析GEMM中的内存访问情况。
对于一个给定的矩阵乘法问题,计算C = A × B,可以表示为元素级表达式:
其中矩阵A、B和C的大小分别为m×k、k×n和m×n。使用CPU循环的传统方法进行内存访问的总次数为:
其中,m、n、k是累加求和的循环次数;2、1和1分别是访问C、A和B所需的频率,这涉及数据传输延迟。基于上述例子,内存访问次数为$4 × 100 × 400 × 80 = 1.28 × 10^7$。
如果使用PIM进行计算,内存访问频率RT_PIM可以描述如下:
其中,$parRowA = m$,$parColA = k/length(input_{col})$,$parRowB = k/length(PIM_{row})$,$parColB = n/length(PIM_{col})$。parRowA、parColA、parRowB、parColB分别表示在PIM输入缓冲区和PIM内存中分区的矩阵A和B的数量。Inputcol是输入缓冲区的大小,而PIMrow和PIMcol是PIM内存的大小。
回到上述例子中,内存访问次数减少到:$ 6 \cdot 100 \cdot 400/64 \cdot 80/16 = 2.1 \times 10^4 $
(PIM内存带来了100倍的减少)。
通过使用多核和提出的拼接方法,PIM内存中的权重数据在最大程度上保持不变,内存访问频率进一步降低为:
然后,在上述相同的例子中,通过使用提出的拼接方法,内存访问次数可以进一步减少到:
$ \frac{400}{64} \times \frac{80}{16} \times (2 + 4 \times 100) = 1.407 \times 10^4 $
(由于提出的拼接方法,又减少了1.5倍)。
5 Evaluation
5.A Simulation Setup
我们使用文献【3】中的最新设计作为目标PIM内存实现。每两个核心结合不同的数字显著性,以获得输入和权重的8位精度,形成4个PIM内存并行工作。每个等效的PIM内存在维度为V、W、I分别为1×64、64×16和1×16的情况下执行I = VW操作。根据表I,每次PIM矩阵操作在基本工作时钟频率为1GHz的情况下需要19个周期。为了提供足够的总线带宽,我们按照图5中的相同配置,将AHB总线的事务大小设置为64字节。针对AIoT应用场景,基线是最新的嵌入式TinyML处理器【18】。
5.B Compute Latency
图8(a)显示了计算延迟的结果。x轴表示输入矩阵的维度,y轴表示相对于内存访问(包括指令解码和总线传输延迟)的单位时间的相对计算延迟,以对数刻度表示。在图8(b)的柱状图中,当输入维度从4096增加到5184时,加速率下降。因为传输的数据大小不足以填满整个PIM内存,因此空间利用率降低。与基线TinyML处理器在仅GEMM基准测试中的表现相比,PIMopt模型可以将性能提高约430倍。与优化前的PIM模型相比,提出的PIMopt可以将性能提高约11倍。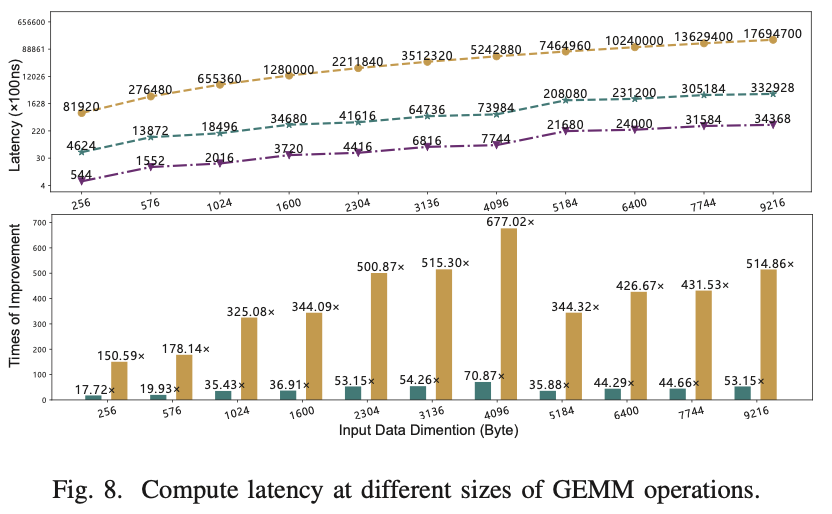
5.C Area and Power Efficiency
我们使用Verilog HDL在28nm商业工艺设计套件中实现了AHB从属设备。比较结果,包括与PUMA【10】的比较,列在表III中。PUMA的结果根据【10】中的数据估算并缩放到28nm节点。由于HMA设计去除了占主导地位的片上网络基础设施,相同2Mb PIM内存在28nm工艺下的总体面积减少了44.6%。我们仅比较了连接到SoC接口的平均功耗,不包括PIM内存、指令内存和额外的输出缓冲区。HMA大大简化了互连网络设计,使2Mb PIM内存的外围电路活动功耗减少了416倍。
5.D DNN Acceleration Analysis
为了研究HMA在实际DNN推理任务中的性能提升,我们选择了6个广泛使用的DNN基准:LeNet、AlexNet、VGG-16、VGG-19、ResNet-18和MobileNet【19】。结果如图9所示,其中y轴表示延迟的自然对数,x轴描述了每个基准的层数。在所有这些实际情况下,“pim optimized”在每层中的速度提高了11.0倍,无论是卷积层还是全连接层的维度。在这些神经网络中,MobileNet具有深而窄的神经网络结构——深度可分离卷积的形状导致了图9中显示的波动趋势。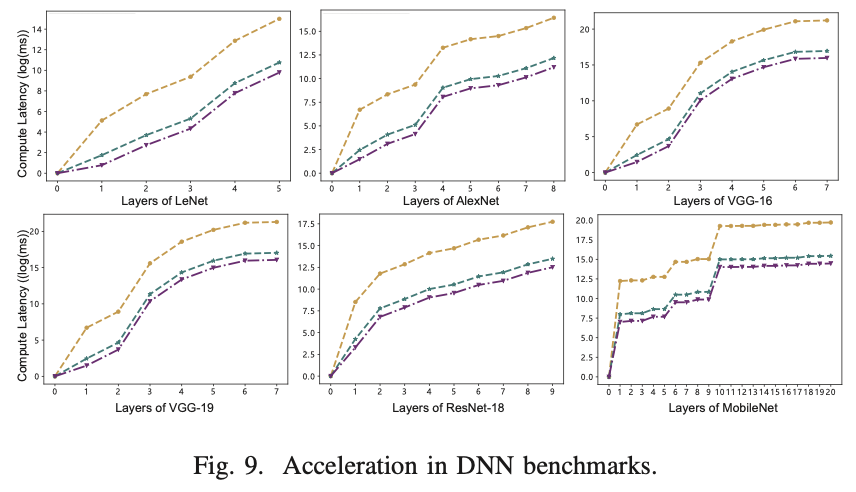
6 Conclusion
在这项工作中,我们提出了一种异构内存架构,以提高PIM在传统小型嵌入式SoC上的效率。在此基础上,我们进一步提出了一种映射算法,以更好地利用PIM的加速能力。功耗和操作延迟在多种常见的AIoT应用下进行了全面探讨。该分析可以为PIM相关SoC设计在其早期设计阶段提供高层次软硬件协同设计的重要指导。