通俗理解llama3的性能和创新
本文最后更新于 2024年7月21日凌晨12点08分
通俗理解llama3模型的性能和创新
2024年4月18日, Meta官方发布了text-based llama3大模型, 这是最新一代的large language model (LLM).
这个text-based model是llama3系列模型中的第一个, 之后会让llama3实现多语言(multilingual)和多模态(multimodal), 实现更长context上下文, 并提高推理和编码(reasoning and coding)的整体性能.
模型性能 state-of-the-art performance
目前, llama3模型有8B参数和70B参数两个预训练版本, 在很多基准(benchmarks)上有最好(state-of-the-art)的表现. 是目前最好的开源模型之一.
新的8B和70B参数的llama3模型相比llama2有重大飞跃. 得益于预训练(pretraining)和后训练(post-training)的改进, 这个预训练和指令微调模型(instruction-fine-tuned)是目前在8B和70B参数规模上最好的模型. 在后训练程序上的改进大大降低了错误拒接率(false refusal rates), 提高了对齐率(alignment), 增强了模型响应多样性. 在推理(reasoning), 代码生成(code generation)和指令跟踪(instruction following)上有极大改进.
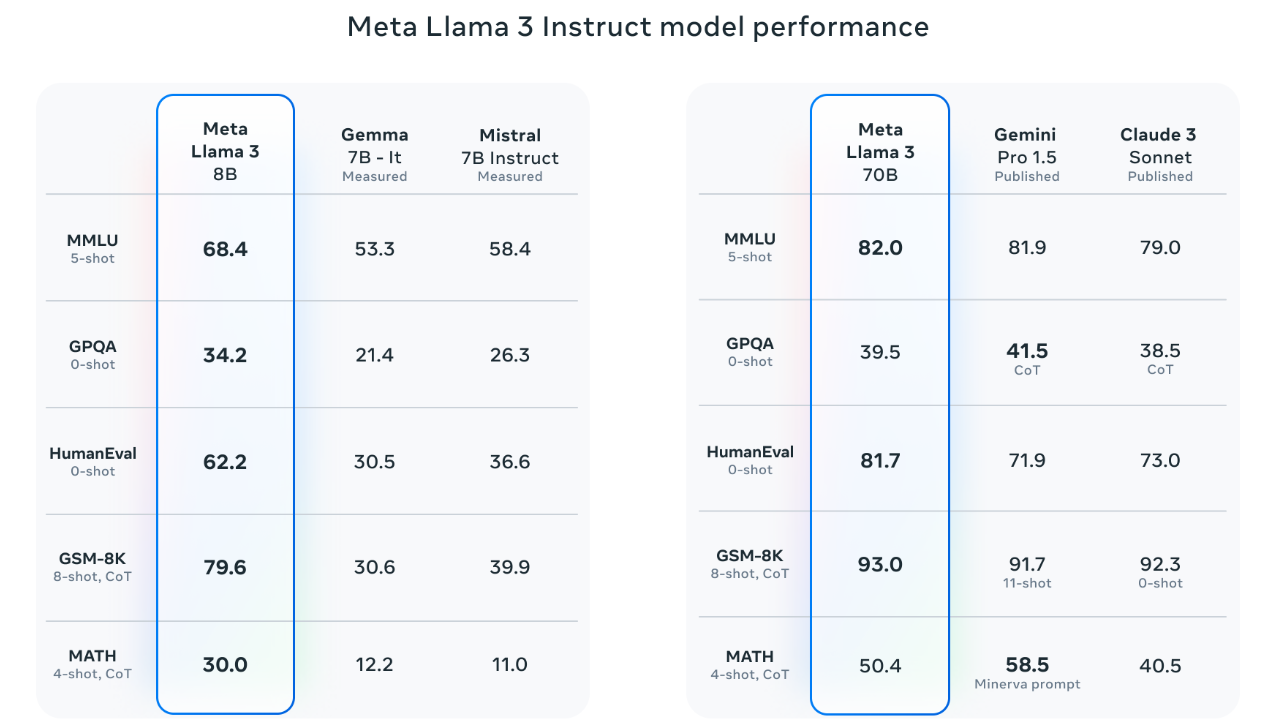
具体评估细节看这个: https://github.com/meta-llama/llama3/blob/main/eval_details.md
在开发llama3的时候, 除了在标准benchmarks上评估其性能, 为了优化模型在实际场景中的表现, 他们还开发了一个新的高质量人工评估集(high-quality human evaluation set). 这个评估集包含1800个prompts, 其中蕴含12个关键用例: asking for advice征求建议, brainstorming头脑风暴, classification分类, closed question answering封闭式问答, coding编码, creative writing创意写作, extraction提取, inhabiting a character/persona扮演人物角色, open question answering开放式问答, reasoning推理, rewriting重写, summarization总结. 为了防止模型在这个评估集上过度拟合, 甚至他们自己的建模团队也不能访问它.
下面这个图显示了在这个评估集上的人工评估结果, 对比LLama3 70B和Claude Sonnet/ Mistral Medium/GPT-3.5/Meta Llama2: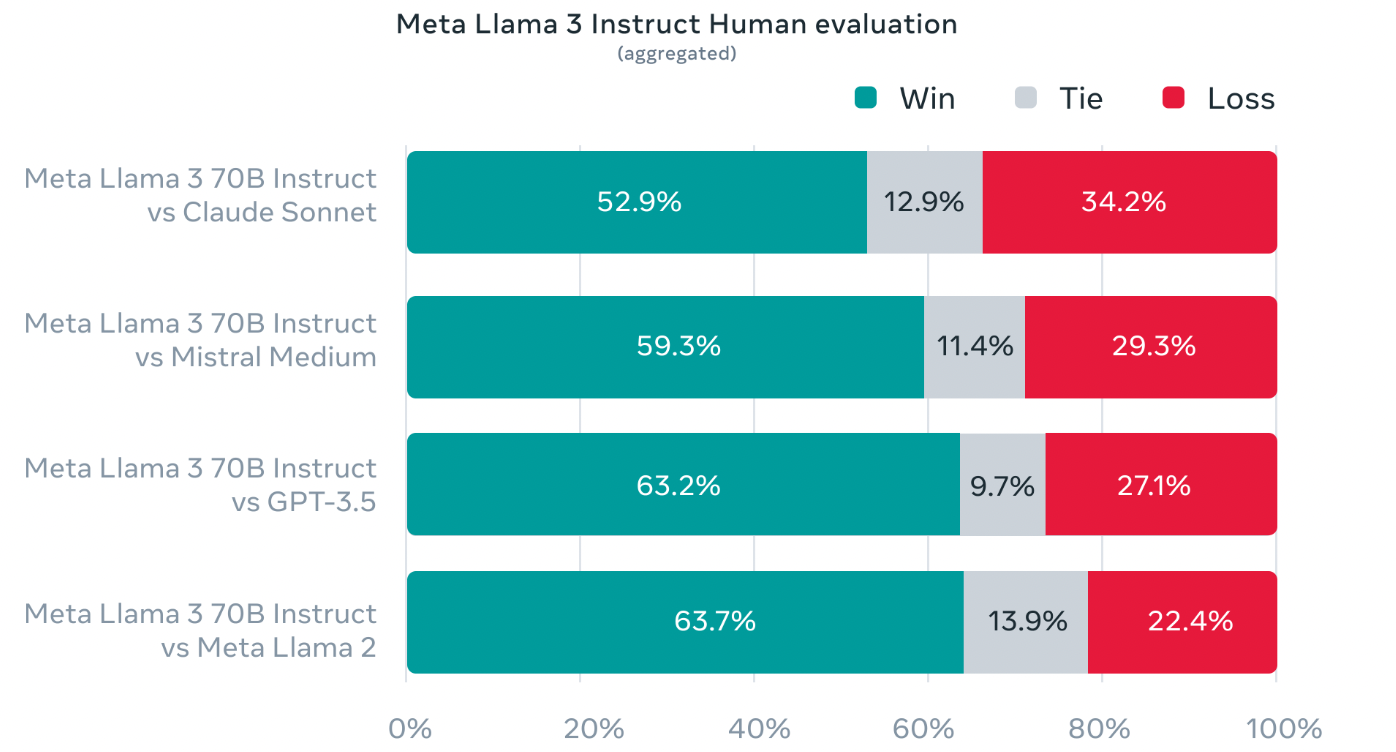
llama3预训练模型还在这些评估维度上刷新了性能, 建立了新的state-of-the-art: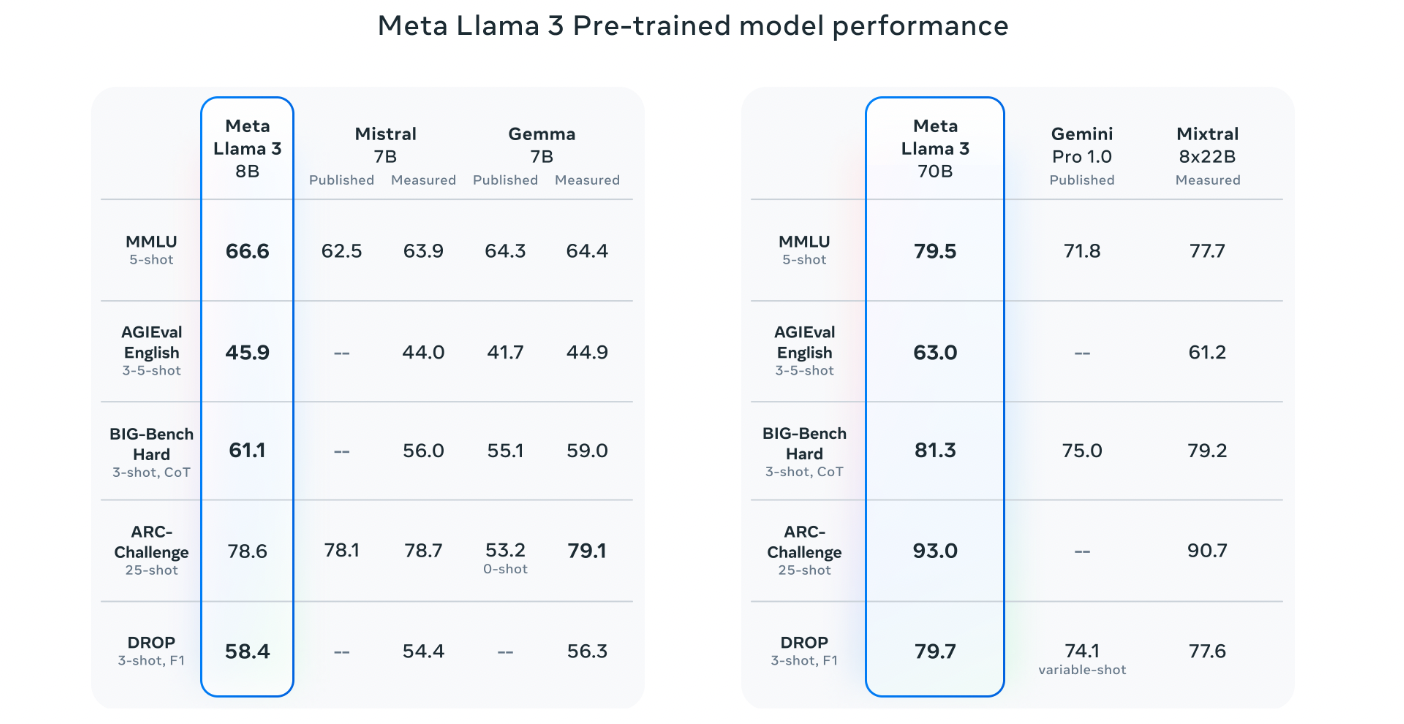
注意, 这个图3和上面的图1很像, 但是有区别. 其一是评估方法有些不同, 其二: 图3是预训练模型的性能, 图1是instruct模型的性能.
模型原理详解
为了开发优秀的LLM, 创新/扩展/优化简化这三个方面很重要. 下面围绕着四个维度较少llama3模型: 模型架构(model architecture(pretraining data), 扩展预训练(scaling up pretraining), 指令微调(instruction fine-tuning).
模型结构
llama3使用transformer的decoder结构, 和llama2相比, 有这样几个改进:
- llama3的tokenizer使用含有128K个tokens的词汇表, 能更有效的对语言进行编码.
- 为了提高llama3的推理效率(inference efficiency), 采用分组查询注意(grouped query attention GQA).
- 使用含有8192个tokens的序列(sequences)对模型训练, 使用mask(掩码)来保证self-attention不会cross document boundaries(跨越文本边界)
训练数据
为了训练最佳的LLM, 高质量的训练集很重要. llama3使用超过15T的tokens来预训练, 这些tokens都来自于公开来源. llama3的训练时间是llama2的7倍, 代码量是其4倍. 为了应对即将来到的多语言用例, 预训练数据中有超过5%是非英文的, 由30多种语言. 但是在这些非英语上的性能会不如英语.
为了保证预训练数据的高质量, 他们开发了一系列的数据过滤管道(data-filtering pipelines), 这些pipelines包含heuristic filters(启发式过滤器), NSFW filters, semantic deduplication approaches(语义重复删除方法), 和text-quality classifier(文本质量分类器). 使用llama2生成训练数据用于llama3的文本质量分类器.
他们还进行实验以评估如何把不同来源的数据混合用于最终预训练的最优方式. 以确保能选择一种混合数据, 让llama3在各种用例(琐事, 历史, 编程等)均表现良好.
扩展预训练
扩展预训练, 通俗而言, 就是在使用大量数据集对模型预训练后, 如何让预训练模型更好的实现下游任务, 通过小的微调或者优化在下游实现好的性能.
llama3指定了一系列详细的扩展法则用于下游基准评定. 这些扩展法则让我们能选择最优数据组合, 对如何使用训练计算做出明智决策. 扩展法则还能让我们在实际训练模型之前预测模型在关键任务上的表现.
有关扩展行为的新发现: 尽管我们发现8B模型的Chinchilla最优训练计算量对应于200B个tokens, 但是在使用两个数据集以上的数据对模型训练后, 模型性能仍会继续提升. 使用高达15T的tokens对8B和70B模型训练后, 模型持续呈对数线性改善性能.
(是否可以理解为: llama模型的性能会随着数据量的增大而增大, 不论数据量有多大. 不会像CNN一样, 性能随着数据量的增大而先增大后减小)
并行化: 结合了三种并行, 数据并行化, 模型并行化, 和管道并行化.
指令微调
llama3对指令微调方法进行了创新. 他的后训练方法(post-training)包含: 监督微调(supervised fine-tuning SFT), 拒接采样(rejection sampling), 近端策略优化(proximal policy optimization PPO), 直接偏好优化(direct preference optimization DPO).
SFT中的prompt质量和PPO&DPO中的偏好排名对对齐模型(aligned model)的性能有很大影响. 因此, 需要精心整理训练数据, 并对人工标注多轮质量保证.
通过 PPO 和 DPO 从偏好排名中学习也大大提高了 Llama 3 在推理和编码任务上的性能。我们发现,如果你问一个模型一个它很难回答的推理问题,模型有时会产生正确的推理轨迹:模型知道如何产生正确的答案,但不知道如何选择它。对偏好排名进行训练使模型能够学习如何选择它。
构建llama3
为了让开发人员更方便自定义llama3, 他们有构建新的pytorch库和入门指南. 关于llama3的代码实现之后再讲.
并且, 他们还构建了一个系统级方法, 让开发者和使用者最大化的部署和使用llama系列模型.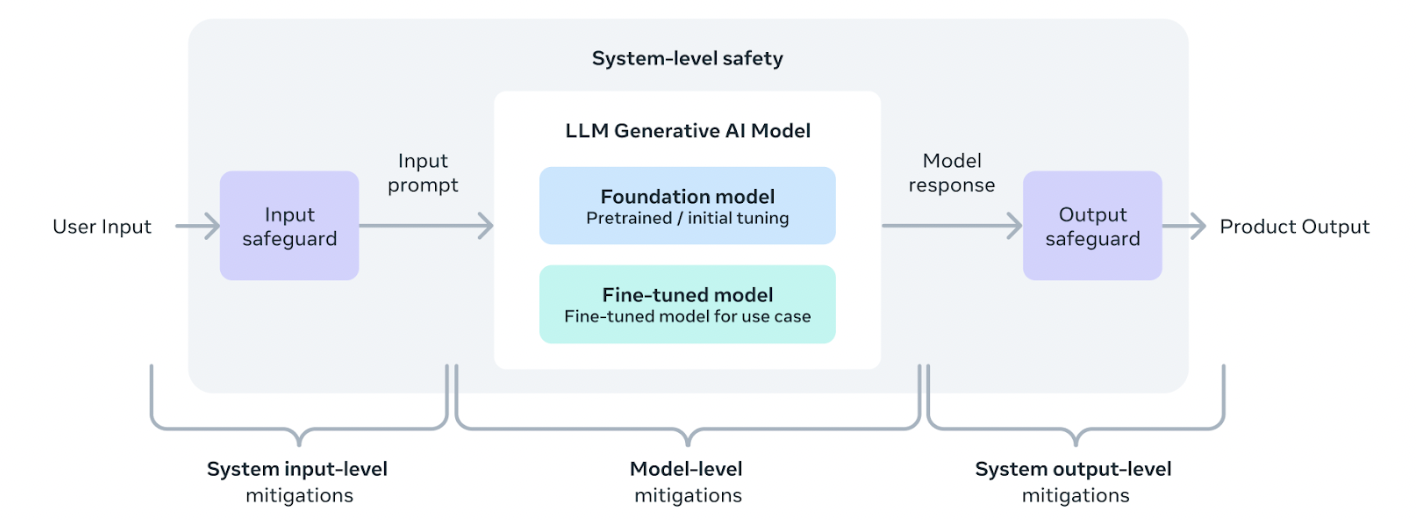
关于如何使用llama3的功能, 这里有详细说明: Llama Recipes, 包含所有llama3开源代码, 从微调到模型评估.
总结
llama3的8B和70B模型只是llama3系列的开始, 之后几个月会发布更多功能, 最大的模型有400B仍在训练中. 之后会发布包含多模态/多语言/更长上下文等具有新功能的模型. 完成llama3的训练后, Meta团队会写一个详细的研究论文.
写在最后
本文只是大概介绍了llama3的结构和评估, 但是有几个方面需要具体解释下:
- llama系列模型的具体结构.
- llama模型的代码实现.
- 区分这四者: instruct learning, prompt learning和fine-tuning, instruction fine-tuning.
- LLM的评估指标有哪些, 例如图1中的MMLU, GPQA, HumanEval, GSM-8K, MATH是什么意思?
- scaling up pretraining扩展预训练是什么意思?
- llama3中的分组查询策略是什么?
这些细节问题请看其他博客.
资源链接
llama3的github代码: llama3 github
llama3结构详解的官方文章: Introducing Meta Llama 3: The most capable openly available LLM to date
AI模型的Meta官方blog: AI news from Meta
访问这个网站下载模型: Llama3 website
这里是llama3入门指南: Getting Started Guide
这是如何使用llama的github示例: Llama Recipes