llama2模型的结构和原理
本文最后更新于 2024年7月31日下午4点52分
llama2模型的原理和代码详解
llama2模型是Meta在2023年3月份左右提出的大语言模型. 它声称以更小的体积, 在多数任务上超过GPT-3的性能.
模型的github代码和research paper看下方的资源链接.
下面我会结合llama2的官方源码来通俗解释llama2是如何实现文本生成和对话功能.
整体流程
简单而言, llama2的流程是这样的(以文本补全为例):
输入一段文本, 首先使用tokenizer得到一组token-ids的序列, 然后输入给transformer结构预测next tokens序列, 然后再用detokenizer得到文本.
我们结合源代码分析, 我的分析步骤是从整体到局部, 从宏观到细节, 逐步深入.
llama2的代码主要是这三个文件:1
2
3generation.py # 构建llama类, 其中self.model调用model.py文件的Transformer类, self.tokenizer调用tokenizer.py的Tokenizer类
tokenizer.py # 构建基于SentencePiece的Tokenizer类, 用于文本的tokenize和detokenize
model.py # 构建Transformer类, 实现基于transfomer decoder的llama2结构
文本补全和对话任务的示例看源代码的这两个文件:1
2example_chat_completion.py
example_text_completion.py
文本补全为例 example_text_completion.py
以文本补全为例, 看源码文件的顺序是:1
2
3
4先看example_text_completion.py整体过程;
然后看generation.py, 如何构造llama类以及如何得到预测tokens;
再然后看tokenizer.py, 怎么构建SentencePiece分词器;
最后也是最重要的部分是model.py, llama2模型是如何基于transfomer decoder构建的.
首先分析example_text_completion.py, 文本补全大致分为三步:
- 创建一个generator, 其中Llama.build使用的generation.py文件的Llama类的build函数, tokenizer_path是tokenizer model的存储路径:
1
2
3
4
5
6generator = Llama.build(
ckpt_dir=ckpt_dir,
tokenizer_path=tokenizer_path,
max_seq_len=max_seq_len,
max_batch_size=max_batch_size,
) - 编写自己的prompts, 注意prompts是list数组, 里面包含多个prompt.
- 把prompts输入给generator的text_completion函数, 得到results, 其中result[‘generation’]就是续写文本.
1
2
3
4
5
6
7
8
9results = generator.text_completion(
prompts,
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
)
for result in results:
print(result['generation'])
构造llama实例和tokens预测 generation.py
这里看generation.py文件.
1. build函数
首先是build函数构建llama instance.1
2
3
4
5
6
7
8def build(
ckpt_dir: str, # checkpoint file的路径, 用于加载预训练模型
tokenizer_path: str, # tokenizer路径
max_seq_len: int, # sequence的最大长度
max_batch_size: int, # 用于推理的batch size的最大值
model_parallel_size: Optional[int] = None, # 模型并行运算的数目, 默认为None, 如果没提供该参数, 由环境决定并行数.
seed: int = 1,
) -> "Llama": # 返回一个llama实例 Llama(model, tokenizer)
这里最重要的就是加载tokenizer和加载model:1
2tokenizer = Tokenizer(model_path=tokenizer_path)
model = Transformer(model_args)
在这一层, 我们先不分析tokenizer和model的细节. 只需要知道: tokenizer的encode会把输入的文本转为token ids, 即输入一句话, 会转换为一个列表, 元素都是0~vocab_size的整数, 其中vocab_size是词表长度; decode会把token ids转为文本.
model的输入是一组的token ids, 输出一个概率向量logits, 表示词汇表中的每个token的预测概率.
2. text_completion
先不看logprobs, 假设其为false.
bluid构造好之后, 会使用text_completion函数, 这里输入的是prompts(由多个prompt句子组成的列表), 和一些参数.
首先对每个prompt使用tokenizer进行编码:1
prompt_tokens = [self.tokenizer.encode(x, bos=True, eos=False) for x in prompts]
然后把得到的prompt_tokens输入给generate函数, 得到generation_tokens:1
2
3
4
5
6
7
8generation_tokens, generation_logprobs = self.generate(
prompt_tokens=prompt_tokens,
max_gen_len=max_gen_len,
temperature=temperature,
top_p=top_p,
logprobs=logprobs,
echo=echo,
)
generation_tokens就是预测的tokens序列, 然后使用tokenizer.decode解码得到回答文本.1
return [{"generation": self.tokenizer.decode(t)} for t in generation_tokens]
3. generate函数
(为了方便理解, 简略源码步骤, 假设logprobs=false)
generate是Llama类中最重要的函数, 输入是二维列表的pormpt tokens, 输出的预测tokens也是二维列表.
首先分清楚prompt_len, gen_len, seq_len这几个概念. prompt_len是输入的prompt文本经过tokenizer转为token ids之后的数组长度, 比如一句话’hello world’转为[324, 25, 82], 则prompt_len=3. gen_len是生成的token ids列表的长度, 会有一个最大长度的限制max_gen_len, 防止模型无限生成. seq_len是输入给transformer的序列的长度, 会有一个最大长度限制max_seq_len.
一般地, max_seq_len会大于max_gen_len+max_prompt_len. 让tokens向量的前半部分存储prompt_ids, 后半部分存储gen_ids.
首先得到total_len和batch size=bsz, 然后构造初始tokens张量, 其形状为(bsz, total_len), 初始用pad_id填充. 然后给tokens每一行的前半部分填入prompt_token:1
2
3
4
5bsz = len(prompt_tokens)
total_len = min(params.max_seq_len, max_gen_len + max_prompt_len)
tokens = torch.full((bsz, total_len), pad_id, dtype=torch.long, device="cuda")
for k, t in enumerate(prompt_tokens):
tokens[k, : len(t)] = torch.tensor(t, dtype=torch.long, device="cuda")
tokens的后半部分填next_token, 即预测token. 这是由一个for循环一步一步实现的. 每次给model输入tokens[:, prev_pos:cur_pos]部分, 得到logits预测向量, 其中概率最大的对应下标为next_token, 填写入cur_pos, 更新prev_pos:1
2
3
4
5for cur_pos in range(min_prompt_len, total_len):
logits = self.model.forward(tokens[:, prev_pos:cur_pos], prev_pos)
next_token = torch.argmax(logits[:, -1], dim=-1)
tokens[:, cur_pos] = next_token
prev_pos = cur_pos
最终返回out_tokens. 得到tokens张量后, 提取其中的后半部分, 也就是next_tokens部分, 是预测的token ids, 输出为out_tokens. 如果后半部分由eos_id(EOS是特殊符号, 表示结束), 只提取start到eos_idx之间的部分:1
2
3
4
5
6
7for i, toks in enumerate(tokens.tolist()):
start = len(prompt_tokens[i])
toks = toks[start : len(prompt_tokens[i]) + max_gen_len]
if self.tokenizer.eos_id in toks:
eos_idx = toks.index(self.tokenizer.eos_id)
toks = toks[:eos_idx]
return out_tokens
tokenizer分词器
上面介绍了整体流程, 下面看tokenizer和model结构的细节.
tokenizer.py文件很简单. 首先需要一个model_path, 就是tokenizer模型的路径, 然后调用SentencePieceProcessor构建sentencepiece模型:1
self.sp_model = SentencePieceProcessor(model_file=model_path)
其中, 模型的词表长度, BOS/EOS/PAD特殊字符的id等, 这些信息保存在self当中:1
2
3
4self.n_words: int = self.sp_model.vocab_size()
self.bos_id: int = self.sp_model.bos_id()
self.eos_id: int = self.sp_model.eos_id()
self.pad_id: int = self.sp_model.pad_id()
然后定义encode函数, 用于把string变为sequence = list of token ids, 布尔参数bos和eos表示是否需要给sequence添加bos或者eos符号:1
2
3
4
5
6
7def encode(self, s: str, bos: bool, eos: bool) -> List[int]:
t = self.sp_model.encode(s)
if bos:
t = [self.bos_id] + t
if eos:
t = t + [self.eos_id]
return t
decode函数, 把list of token ids变为string:1
2def decode(self, t: List[int]) -> str:
return self.sp_model.decode(t)
关于sentencepiece的详细介绍, 可以看这个博客: 详细介绍Google的SentencePiece.
模型结构 model.py
下面看model.py文件. 从整体到局部分别是这样几个类:1
2
3
4class Transformer # 首先经过N个TransformerBlock, 然后是RMSnorm, 最后是output层.
class TransformerBlock # 包含Attention层和FeedForward层, 有residual connection(残差连接), 和RMSnorm.
class FeedForward # 有silu激活函数的全连接层
class Attention # 实现output=softmax(q*keys/sqrt(head_dim))*values, 有rotary_embedding技术, 和cache_k, cache_v缓存技术.
Transformer类
输入的tokens是一个 token indices列表。 首先需要经过一个token embedding函数(ParallelEmbedding)把 token indices列表当中的每个整数转换成向量.
input embedding原理
大致原理是, 有一个weight矩阵, 大小是vocab_size * embedding_dim, 其中vocab_size是词表大小, embedding_dim是每个token id经过embedding变为向量后的长度, 即size of hidden state.
例如现在有$\text{token_ids_list} = [32, 124, 41]$, 一个weight矩阵大小是$105$, 表示词表中总共有10个token。 然后embedding_dim的大小为 5。 则每个token id整数会向量化为大小为$ 5 1 $的向量, 这个token_ids_list经过input embedding会变为大小为$3*5$的张量.
训练好这个这个weight矩阵后, 对每个token id, 都可以通过查表(lookup table), 直接查看weight矩阵的对应行, 得到词向量. 如何构建这个weight矩阵呢? 这里不详细讲解. 可以看这一篇tokenizer的原理I.
然后经过layers个TransformerBlock模块:
先通过params.n_layers定义有几层, 存储在self.layers中. 每一层是一个TransformerBlock, 输入是tokens和start_pos, 得到输出.
最后 经过RMSNorm层和output层, 得到最终输出. output层是一个列并行的linear层: ColumnParallelLinear.
这里是init函数的参数定义:1
2
3
4
5
6
7
8
9
10
11self.tok_embeddings = ParallelEmbedding(
params.vocab_size, params.dim, init_method=lambda x: x
)
for layer_id in range(params.n_layers):
self.layers.append(TransformerBlock(layer_id, params))
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
self.output = ColumnParallelLinear(
params.dim, params.vocab_size, bias=False, init_method=lambda x: x
)
这里是forward函数的前向传播过程:1
2
3
4
5
6
7
8h = self.tok_embeddings(tokens)
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask)
h = self.norm(h)
output = self.output(h).float()
return output
TransformerBlock类
首先是TransformerBlock.init函数:1
2
3
4
5
6
7
8
9self.attention = Attention(args)
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.feed_forward = FeedForward(
dim=args.dim,
hidden_dim=4 * args.dim,
multiple_of=args.multiple_of,
ffn_dim_multiplier=args.ffn_dim_multiplier,
)
然后是forward前向传播:1
2
3
4
5h = x + self.attention(
self.attention_norm(x), start_pos, freqs_cis, mask
)
out = h + self.feed_forward(self.ffn_norm(h))
return out
这个TransformerBlock模块很重要, 结构可以分为两大块, 首先是Attention块, 然后是FeedForward块. 每个块里面都有pre-norm的RMSnorm(pre-norm表示norm操作在残差连接之前), 和residual connection.
Attention类
Attention层是transformer模型的重要结构, 一言以蔽之就是这个公式:
细节如下:
- 输入的x分别经过三个ColumnParallelLinear层$w_q, w_k, w_v$, 得到$x_q, x_k, x_v$.
- 然后$x_q, x_k$经过rotary embedding变换.
- $x_k, x_v$经过cache缓存更新, 得到keys和values.
- $x_q$和keys计算scores注意力得分, 再经过softmax, 然后和values相乘, 得到output.
- 最后通过一个$w_o$的linear层, 得到输出.
这里重点就是rotary embedding是什么, kv的cache缓存作用. 这两点在后面会详细讲.
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# step 1:
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
# step 2:
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
# step 3:
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
# step 4:
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)
# step 5:
return self.wo(output)
FeedForward类
FeedForward的forward函数很简单:1
2def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
需要注意的是, 里面有silu激活函数, 并且linear层(即w1, w2, w3层)是ColumnParallelLinear的.
FFN前馈神经网络
FFN(feed forward network)前馈神经网络. 就是两层的MLP(Multilayer Perceptron多层感知机), 第一层MLP会把输入的向量升维, 然后经过激活激活函数, 再第二层MLP会把向量降维.
FFN公式如下, 以ReLU激活函数为例:
也可能会把偏置项去掉:
原来使用的ReLU激活函数, 在这里把ReLU替换为SiLU激活函数.
llama2的创新点
通过上面model.py代码的介绍, 我们知道了llama2的大致流程, 下面会针对这几个特点详细介绍其原理, 并结合代码分析:
- ColumnParallelLinear
- Pre-norm和Post-norm
- RMSnorm (Root Mean Square Layer Normalization), pre-norm和post-norm
- SiLU激活函数 (也叫Swish激活函数)
- rotary embedding (RoPE旋转位置编码)
- KV cache缓存
ColumnParallelLinear
在model.py中很多次使用到ColumnParallelLinear, 例如Attention类的$w_q, w_k, w_v$, FeedForward层也使用ColumnParallelLinear, 还有最后的output层.
其实ColumnParallelLinear就是一种特殊的linear layer, 列并行运算的线性层. 假设现在有p个gpu, 在执行矩阵乘法$Y = XA + b$时, 会把A按照列分割为$A = [A_1, A_2, …, A_p]$, 也就是对权重矩阵沿着最后一个维度划分, 每个gpu执行$Y_i = X A_i + b_i$.
为了方便理解, 这里就将其当作普通的linear layer即可.
Pre-Norm和Post-Norm
Bert模型采用的Post-Norm方法, Llama模型采用的Pre-Norm方法. 这两个方法有什么区别?
简单而言, Post-Norm就是在Add操作之后进行Norm操作. 而Pre-Norm就是在Norm之后进行Add操作. 其中Add操作就是残差连接$F(x)+x$, Norm就是归一化操作, 例如Layer Norm, Group Norm, Batch Norm, Instance Norm是不同的归一化方法.
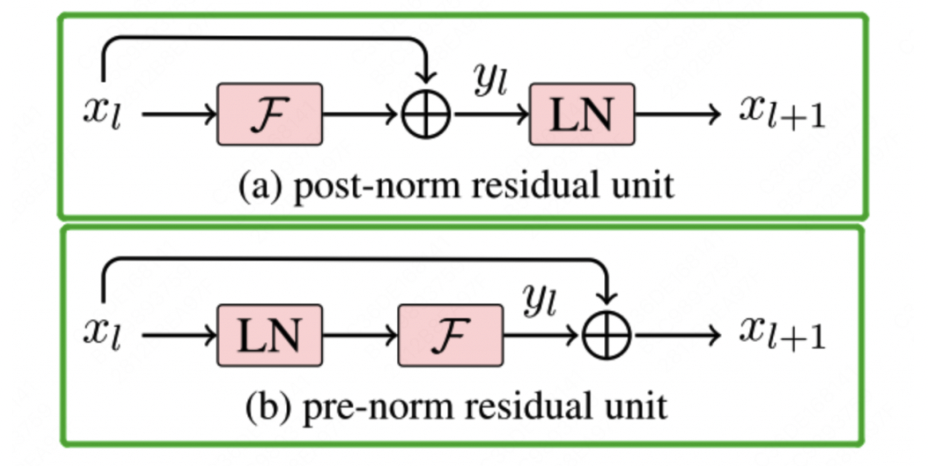
Post-Norm的公式:
Pre-Norm的公式:
llama2的post-norm体现在TransformerBLock类里面, block里面不论是attention块还是feefforward块都是先进行RMSnorm, 然后residual connection:1
2
3
4h = x + self.attention(
self.attention_norm(x), start_pos, freqs_cis, mask
)
out = h + self.feed_forward(self.ffn_norm(h))
RMS Norm
RMS Normalization也是一种归一化方法, 全称Root Mean Square Normalization, 是对LayerNorm的改进. RMS Norm没有做re-center操作(移除了LayerNorm分子的均值项), 不是使用的整个样本的均值和方差, 而是使用的平方根的均值来归一化.
RMS Norm的公式:
model.py的RMSNorm类的代码, 其中rsqrt是平方跟的倒数$\frac{1}{\sqrt{ \cdot }}$, eps是小的正数 防止除数为零, mean求均值是沿着最后一个维度进行, 并保持原来的维度不变:1
output = x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
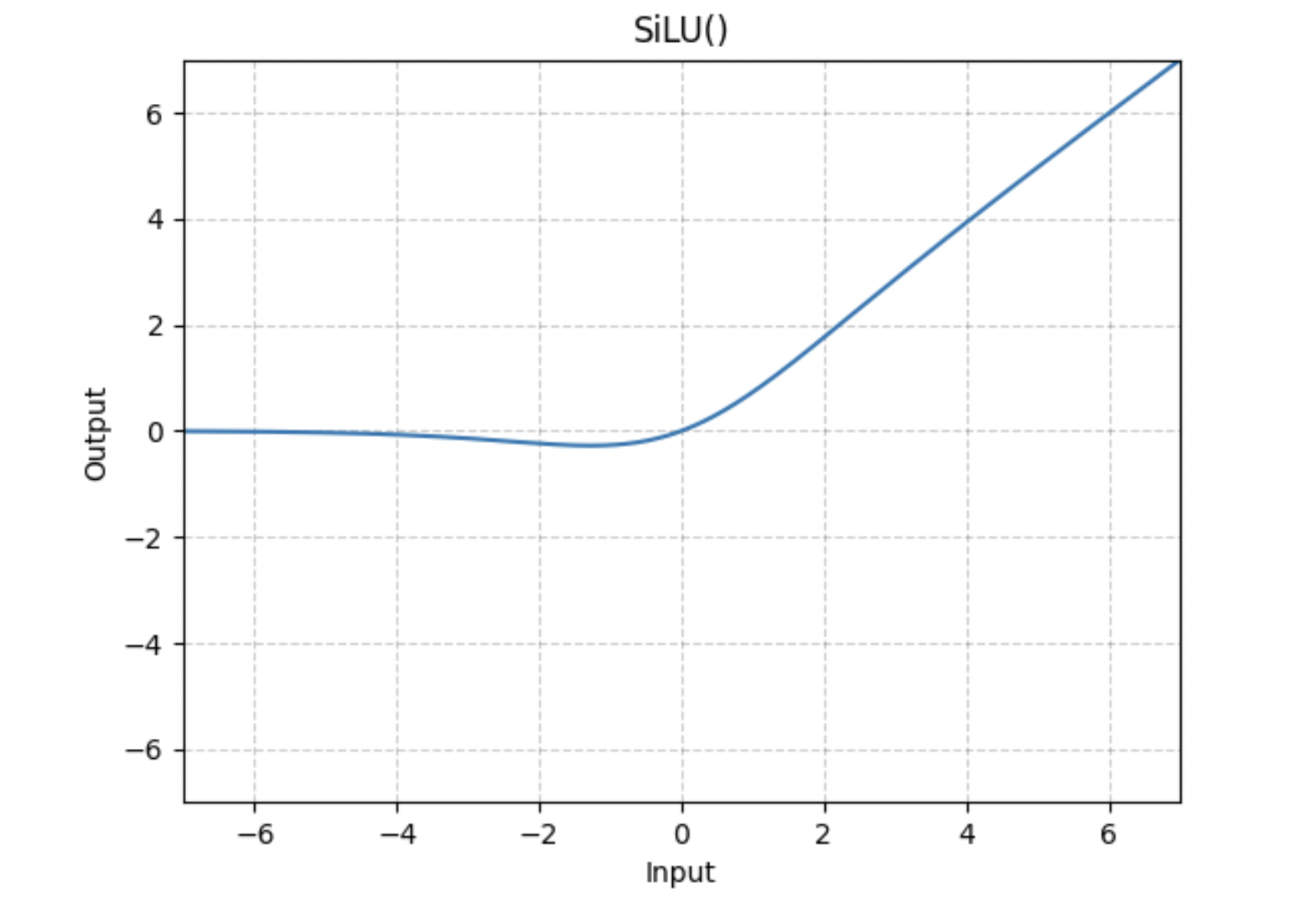
SiLU激活函数
SiLU全称Sigmoid Linear Unit, 也叫做Swish function, 是2017年提出的. SiLU是Sigmoid和ReLU的改进版, 具备无上界有下界、平滑、非单调的特性。SiLU在深层模型上的效果优于ReLU。可以看做是平滑的ReLU激活函数。
SiLU激活函数的公式:
在model.py代码中, silu激活函数使用于FeedForward层:1
2
3class FeedForward(nn.Module):
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
SiLU激活函数来自于GELUs(Gaussian Error Linear Units), 也可以看看这两个论文Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning, Swish: a Self-Gated Activation Function.
RoPE旋转位置编码
在transformer模型当中位置编码是必不可少的, 因为对于输入的文本来说,上下文关系很重要, 但是纯粹的attention模块是无法捕捉输入顺序的。 也就是无法区分不同位置的token.
位置编码可以分为绝对位置编码和相对位置编码. 位置编码的详细原理可以看这个博客位置编码的原理详解, 在这里,我只讲解旋转位置编码的原理。
旋转位置编码是一种相对位置编码。 输入一个句子经过tokenizer之后, 会得到token ids, 而每一个整数id会通过input embedding得到一个向量. 现在我们假设有2个embedding向量q和k, 分别在序列的位置m和位置n上。 向量q和 k的大小都是$d\times 1$, 其中d是 size of hidden state。
注意区分vocabulary size和 size of hidden state。 前者表示的是词汇表的长度, 也就是这个词表当中包含多少个token。 后者表示的是每一个token index转换成的一个向量的长度。
对向量q添加位置为m的旋转位置编码是这样的: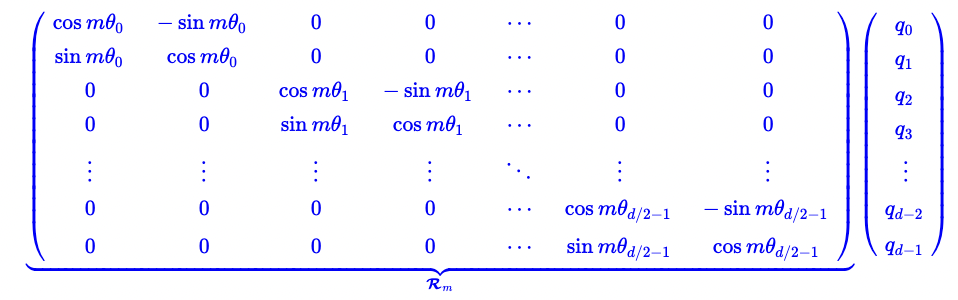
向量q当中有d个元素,我们把它们两两一组。可以看作对于向量$(q_{2i}, q_{2i+1})$顺时针旋转$m \theta$的角度。
也就是说, 旋转位置编码是给位置为m的向量 q乘上矩阵$R_m$, 给位置为n的向量 k乘上矩阵$R_n$。添加旋转位置编码信息后进入attention模块, 向量相乘也会自动包含相对位置信息:
由于R矩阵的稀疏性, 图三当中的矩阵乘法, 也可以使用如下方式来实现:
其中, $\otimes$表示对应位置相乘, 也是numpy计算框架当中的$*$运算。
RoPE位置编码和Sinusoidal位置编码有点相似。 不过 Sinusoidal位置编码是加性的, RoPE可以看做乘性的位置编码。
代码实现是这样的:1
2
3
4
5
6
7
8
9
10
11
12
13
14def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):
ndim = x.ndim
assert 0 <= 1 < ndim
assert freqs_cis.shape == (x.shape[1], x.shape[-1])
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
return freqs_cis.view(*shape)
def apply_rotary_emb():
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
freqs_cis = reshape_for_broadcast(freqs_cis, xq_)
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
KV cache
KV cache就是在模型推理的时候,把每一个token在过attention时乘以$w_k, w_v$这2个参数矩阵的结果缓存下来。 因为推理解码是自回归的方式, 每次生成一个token,都需要依赖之前所有的key和 value, 但是只依赖前一个的query, 所以我们不需要query cache。
如果每次生成下一个token,都需要重新计算前面所有 token的key和value, 这样会有很多的重复计算,所以我们会将之前的key和 value存在缓存当中,直接调用. 并且每次计算,一个新的token的 key和value时, 这个kv cache会随时更新。
我们结合源代码来分析。 kv cache是在attention类当中实现的:1
2
3
4
5
6
7# 输入一个新的token向量x, 计算出新的xk, xv, 然后需要分别更新cache_k, cache_v:
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
# 更新完成后, 拿取缓存当中的所有数据, 作为接下来需要用于计算的keys, values:
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
资源链接和参考
llama2官方GitHub代码: llama2 github code
llama2论文: LLaMA: Open and Efficient Foundation Language Models
llama2 research paper, 有70多页: llama2 research paper
从Meta Llama官网了解前沿llama资讯: Meta Llama官网
GLU论文: GLU论文, SwiGLU论文: SwiGLU论文
参考这几个文章: CSDN: Llama细节和代码, Sniper深度学习笔记, GLU和SwiGLU, 苏剑林—Transformer升级之路:2、博采众长的旋转式位置编码
写在最后
还有部分需要完善:
- post-norm和pre-norm的区别, 哪种情况下使用哪种方法. 参考: https://mingchao.wang/rh9M0DCq/, https://spaces.ac.cn/archives/9009
- 各种归一化normalization方法的介绍和对比. 会另外开一个post介绍.
区分归一化normalization, 标准化standardization, 正则化regularization. 参考: https://www.cnblogs.com/douza/p/14922402.html
位置编码的详细介绍, 绝对位置编码, 相对位置编码. https://kexue.fm/archives/8130. 更新这个博客位置编码的原理详解