llama3.1模型的下载和性能测评
本文最后更新于 2024年8月19日下午5点40分
一文理解llama3.1模型的性能
2024年7月23日, Meta发布了最新的Llama3.1模型, llama3.1中包含了新的405B模型, 更新了之前的llama3 8B和70B模型, 并扩展了context window, 支持8种语言. llama3.1的405B模型在常识(general knowledge), 可操纵性, 数学, 工具使用和多语言翻译等任务中可以与领先的闭源模型相媲美。
Meta llama3.1是支持多语言的大语言模型(multilingual LLMs), 包含8B, 70B, 405B的pretrained和instruction-tuned模型. 目前只支持文本输入和文本/代码输出, 是text-only的, 不支持图片输入输出.
llama3.1支持这8种语言: 英语, 德语, 法语, 意大利语, 葡萄牙语, 印地语, 西班牙语和泰语. 不支持中文. 不过, 模型在更广泛的语言集合上进行过训练, 开发者可以使用这8种语言之外的语言对模型进行微调.
LLama3.1是auto-regressive自回归语言模型, 使用的优化后的transformer架构. 模型的微调使用supervised fine-tuning (SFT)和reinforcement learning with human feedback(RLHF).
llama3.1的训练细节
llama3.1(text only)使用一个新的混合的公开数据集用于训练. 有三个版本: 8B, 70B, 405B. 输入的模态是多语言文本, 输出模态是多语言文本和代码. Context length是128K. 三个版本都使用 grouped-query attention (GQA)训练, 以改善推理能力. 预训练使用的数据token个数超过15T. knowledge cutoff时间是2023年12月, 即模型最新知识更新至23年12月.
目前这个模型是静态的, 训练于离线数据集.
训练时间
使用自定义训练库, 和Meta定制的GPU集群来训练. 使用的GPU是H100-80GB, 累计使用39.3M GPU hours. 其中8B模型的训练时长是1.46M GPU hours, 70B的训练时长是7.0M GPU hours, 405B训练时长是30.84M GPU hours. 训练时长指的是训练每个模型需要的总GPU时间.
训练数据
llama3.1在超过15 trillion tokens上面进行预训练, 是公开的数据集. 微调数据包含公开的指令数据集, 和超过25 million的合成示例.
上面提到的模型参数大小B, 和训练使用的token个数T到底多大:1
2
31M = 1,000,000
1B = 1,000,000,000
1T = 1,000,000,000,000
如何下载llama3.1
主要有两种方法下载llama模型的参数和tokenizer.
首先需要区分两个概念: 模型代码, 和模型的weights与tokenizer.
在GitHub Meta Llama中, 包含了llama2, llama3, llama3.1的模型代码, generate.py, tokenizer.py, model.py. 可以自行下载. 这个代码可以给人们学习理解llama模型的结构原理:1
git clone git@github.com:meta-llama/llama-models.git
但是如果想要运行使用llama3.1模型, 只有这个代码是不够的, 更重要的是权重参数和tokenizer. 参数是使用大量数据pre-train或者instruction-tuned之后的参数, 赋予模型理解和回答的能力, 否则模型只是一个空壳. tokenizer也是通过大量文本训练的分词器.
模型weights和tokenizer的下载和使用需要申请, 可以通过meta llama官网申请, 也可以通过hugging face申请.
huggingface申请
我是用的huggingface来申请使用llama3.1. 首先需要登陆或者注册一个huggingface的账号, 然后进入huggingface-llama3.1, 选择一个版本模型, 我选择的是Meta-Llama-3.1-8B, 然后阅读‘LLAMA 3.1 COMMUNITY LICENSE AGREEMENT’, 填写图1这个表格并提交, 然后等待审核通过.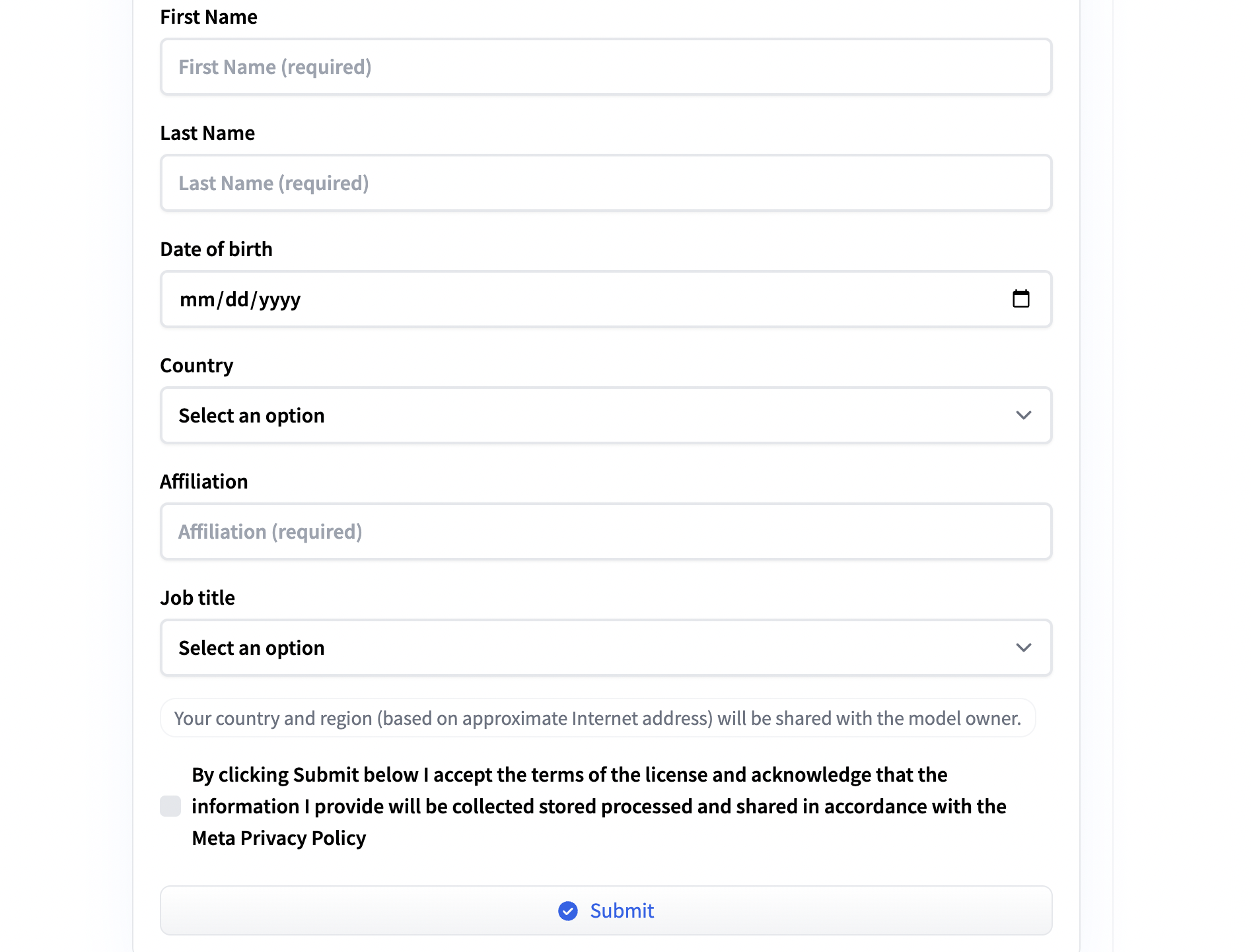
huggingface的申请很快, 基本一小时以内可以申请通过, 当出现‘You have been granted access to this model’字样, 表示你可以使用这个模型了.
huggingface申请通过后, 就能通过huggingface调用llama3.1啦:1
2
3# 注意使用llama3.1, transformer需要 >= 4.43.0
pip install --upgrade transformers
pip list | grep transformers1
2
3
4
5
6
7
8
9
10import transformers
import torch
model_id = "meta-llama/Meta-Llama-3.1-8B"
token = 'your huggingface token'
pipeline = transformers.pipeline(
"text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto", token=token
)
pipeline("Hey how are you doing today?")1
2# output
[{'generated_text': 'Hey how are you doing today? I’m good. I’m just here to talk to you'}]
Meta Llama官网申请
除了用huggingface, 还可以通过Meta llama官网申请下载模型参数和tokenizer: Request Access to Llama Models.
步骤如下:
- 申请下载Request Access to Llama Models.
- 申请通过后, 把github的代码clone到本地: Meta-llama.
1
git clone git@github.com:meta-llama/llama-models.git - 进入本地相关路径, 比如./llama-models/models/llama3_1, 这里面有一个download.sh文件, terminal打开这个路径后运行download.sh文件:
1
2cd ./llama-models/models/llama3_1 # 进入llama3.1模型路径
./download.sh # 运行.sh文件 - 运行sh文件后, 首先会让你输入申请获得的url: ‘Enter the URL from email’. 你把邮件中的url复制到这里, 回车.
然后会有一个model list供你选择, 选择自己想要下载的我选择的都是‘meta-llama-3.1-8b’模型(大概有15G), 选择完毕后他会慢慢下载, 你会发现本地文件夹多了一个‘Meta-Llama-3.1-8B’文件夹, 里面有两个文件: tokenizer.model和.pth文件, 就是tokenizer模型和权重参数文件.1
2
3
4
5
6
7
8
9
10
11
12
13
14**** Model list ***
- meta-llama-3.1-405b
- meta-llama-3.1-70b
- meta-llama-3.1-8b
- meta-llama-guard-3-8b
- prompt-guard
Choose the model to download: meta-llama-3.1-8b
Selected model: meta-llama-3.1-8b
**** Available models to download: ***
- meta-llama-3.1-8b-instruct
- meta-llama-3.1-8b
Enter the list of models to download without spaces or press Enter for all: meta-llama-3.1-8b
benchmark评估
这里, 我使用lm-evaluate-harness工具复现llama3.1的部分evaluation数据, GitHub.
1. lm-eval-harness创建环境
首先使用conda创建一个新的环境, 在这个环境下安装lm-eval-harness. 从github下载lm-eval-harness, 并下载所需的库. 代码如下:1
2
3
4
5conda create --name lm_eval python=3.10
conda activate lm_eval
git clone https://github.com/EleutherAI/lm-evaluation-harness
cd lm-evaluation-harness
pip install -e .
然后查看lm-eval上的所有tasks列表:1
! lm-eval --tasks list
这个task list有很长, 一部分是task输出, 一部分是group输出. 一个group可能包含多个task. 下面我只列出group列表. 后续lm-eval命令的—tasks参数指定下面group list中的一个或者多个任务.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69| Group | Config Location |
|---------------------------------|------------------------------------------------------------------------|
|aclue |lm_eval/tasks/aclue/_aclue.yaml |
|aexams |lm_eval/tasks/aexams/_aexams.yaml |
|agieval |lm_eval/tasks/agieval/agieval.yaml |
|agieval_cn |lm_eval/tasks/agieval/agieval_cn.yaml |
|agieval_en |lm_eval/tasks/agieval/agieval_en.yaml |
|agieval_nous |lm_eval/tasks/agieval/agieval_nous.yaml |
|arabicmmlu |lm_eval/tasks/arabicmmlu/_arabicmmlu.yaml |
|arabicmmlu_humanities |lm_eval/tasks/arabicmmlu/_arabicmmlu_humanities.yaml |
|arabicmmlu_language |lm_eval/tasks/arabicmmlu/_arabicmmlu_language.yaml |
|arabicmmlu_other |lm_eval/tasks/arabicmmlu/_arabicmmlu_other.yaml |
|arabicmmlu_social_science |lm_eval/tasks/arabicmmlu/_arabicmmlu_social_science.yaml |
|arabicmmlu_stem |lm_eval/tasks/arabicmmlu/_arabicmmlu_stem.yaml |
|bbh |lm_eval/tasks/bbh/cot_fewshot/_bbh.yaml |
|bbh_cot_fewshot |lm_eval/tasks/bbh/cot_fewshot/_bbh_cot_fewshot.yaml |
|bbh_cot_zeroshot |lm_eval/tasks/bbh/cot_zeroshot/_bbh_cot_zeroshot.yaml |
|bbh_fewshot |lm_eval/tasks/bbh/fewshot/_bbh_fewshot.yaml |
|bbh_zeroshot |lm_eval/tasks/bbh/zeroshot/_bbh_zeroshot.yaml |
|belebele |lm_eval/tasks/belebele/_belebele.yaml |
|blimp |lm_eval/tasks/blimp/_blimp.yaml |
|ceval-valid |lm_eval/tasks/ceval/_ceval-valid.yaml |
|cmmlu |lm_eval/tasks/cmmlu/_cmmlu.yaml |
|csatqa |lm_eval/tasks/csatqa/_csatqa.yaml |
|flan_held_in |lm_eval/tasks/benchmarks/flan/flan_held_in.yaml |
|flan_held_out |lm_eval/tasks/benchmarks/flan/flan_held_out.yaml |
|haerae |lm_eval/tasks/haerae/_haerae.yaml |
|hendrycks_math |lm_eval/tasks/hendrycks_math/hendrycks_math.yaml |
|kormedmcqa |lm_eval/tasks/kormedmcqa/_kormedmcqa.yaml |
|leaderboard |lm_eval/tasks/leaderboard/leaderboard.yaml |
|leaderboard_bbh |lm_eval/tasks/leaderboard/bbh_mc/_leaderboard_bbh.yaml |
|leaderboard_gpqa |lm_eval/tasks/leaderboard/gpqa/_leaderboard_gpqa.yaml |
|leaderboard_instruction_following|lm_eval/tasks/leaderboard/ifeval/_leaderboard_instruction_following.yaml|
|leaderboard_math_hard |lm_eval/tasks/leaderboard/math/_leaderboard_math.yaml |
|leaderboard_musr |lm_eval/tasks/leaderboard/musr/_musr.yaml |
|med_concepts_qa |lm_eval/tasks/med_concepts_qa/_med_concepts_qa.yaml |
|med_concepts_qa_atc |lm_eval/tasks/med_concepts_qa/_med_concepts_qa_atc.yaml |
|med_concepts_qa_icd10cm |lm_eval/tasks/med_concepts_qa/_med_concepts_qa_icd10cm.yaml |
|med_concepts_qa_icd10proc |lm_eval/tasks/med_concepts_qa/_med_concepts_qa_icd10proc.yaml |
|med_concepts_qa_icd9cm |lm_eval/tasks/med_concepts_qa/_med_concepts_qa_icd9cm.yaml |
|med_concepts_qa_icd9proc |lm_eval/tasks/med_concepts_qa/_med_concepts_qa_icd9proc.yaml |
|minerva_math |lm_eval/tasks/benchmarks/minerva_math.yaml |
|mmlu |lm_eval/tasks/mmlu/default/_mmlu.yaml |
|mmlu_continuation |lm_eval/tasks/mmlu/continuation/_mmlu.yaml |
|mmlu_flan_cot_fewshot |lm_eval/tasks/mmlu/flan_cot_fewshot/_mmlu.yaml |
|mmlu_flan_cot_zeroshot |lm_eval/tasks/mmlu/flan_cot_zeroshot/_mmlu.yaml |
|mmlu_flan_n_shot_generative |lm_eval/tasks/mmlu/flan_n_shot/generative/_mmlu.yaml |
|mmlu_flan_n_shot_loglikelihood |lm_eval/tasks/mmlu/flan_n_shot/loglikelihood/_mmlu.yaml |
|mmlu_generative |lm_eval/tasks/mmlu/generative/_mmlu.yaml |
|mmlu_humanities |lm_eval/tasks/mmlu/default/_mmlu_humanities.yaml |
|mmlu_other |lm_eval/tasks/mmlu/default/_mmlu_other.yaml |
|mmlu_social_sciences |lm_eval/tasks/mmlu/default/_mmlu_social_sciences.yaml |
|mmlu_stem |lm_eval/tasks/mmlu/default/_mmlu_stem.yaml |
|mmlusr |lm_eval/tasks/mmlusr/question_and_answer/_question_and_answer.yaml |
|mmlusr_answer_only |lm_eval/tasks/mmlusr/answer_only/_answer_only.yaml |
|mmlusr_question_only |lm_eval/tasks/mmlusr/question_only/_question_only.yaml |
|multimedqa |lm_eval/tasks/benchmarks/multimedqa/multimedqa.yaml |
|openllm |lm_eval/tasks/benchmarks/openllm.yaml |
|pawsx |lm_eval/tasks/paws-x/_pawsx.yaml |
|pythia |lm_eval/tasks/benchmarks/pythia.yaml |
|t0_eval |lm_eval/tasks/benchmarks/t0_eval.yaml |
|tinyBenchmarks |lm_eval/tasks/tinyBenchmarks/tinyBenchmarks.yaml |
|tmmluplus |lm_eval/tasks/tmmluplus/default/tmmluplus.yaml |
|wmdp |lm_eval/tasks/wmdp/_wmdp.yaml |
|xcopa |lm_eval/tasks/xcopa/_xcopa.yaml |
|xnli |lm_eval/tasks/xnli/_xnli.yaml |
|xstorycloze |lm_eval/tasks/xstorycloze/_xstorycloze.yaml |
|xwinograd |lm_eval/tasks/xwinograd/_xwinograd.yaml |
2. 登陆自己的huggingface
安装好lm-eval环境后, 先使用hf-token在terminal登陆自己的huggingface:1
2pip install huggingface-hub
huggingface-cli login --token your_own_huggingface_token_string
3. 开始评测
lm_eval的常见参数:1
2
3
4
5
6
7
8--model {调用模型的方式, 我使用的huggingface: --model hf, 也可以用其他方式, 具体看官方github.}
--model_args pretrained={这里是huggingface的模型路径}
--tasks {指定任务, 多个任务用逗号分隔, 注意逗号后面不要带空格}
--device {指定使用哪个device, e.g. cuda:0, 注意冒号后面没有空格}
--batch_size {指定batch_size}
--output_path {指定模型评测结果的输出路径, 会在该路径下保存evaluation结果的json文件.}
--use_cache {模型eval结果缓存, 生成一个db文件. 指定use_cache后, 如果这个路径下有上一次保存的cache, 会紧接着上一次的运行, 不用从头开始.
注意, use_cache是路径+文件名前缀. e.g. 如果--use_cache ./eval_cache/llama_eval_cache, 会生成一个./eval_cache/llama_eval_cache_rank0.db文件.}
下面给出llama3.1-8b用lm-eval-harness测评的几个代码示例, 都是直接在terminal输入:
mmlu任务, shot=0和shot=51
2
3
4
5
6
7lm_eval --model hf \
--model_args pretrained=meta-llama/Meta-Llama-3.1-8B,trust_remote_code=true \
--tasks mmlu \
--device cuda:2 \
--batch_size auto:1 \
--output_path ./harness_eval_output \
--use_cache ./harness_eval_cache/Meta-Llama-3.1-8B/llama_eval_cache
1 | |
输出结果形如这样:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72| Tasks |Version|Filter|n-shot|Metric| |Value | |Stderr|
|---------------------------------------|------:|------|-----:|------|---|-----:|---|-----:|
|mmlu | 1|none | |acc |↑ |0.6320|± |0.0038|
| - humanities | 1|none | |acc |↑ |0.5677|± |0.0066|
| - formal_logic | 0|none | 0|acc |↑ |0.4365|± |0.0444|
| - high_school_european_history | 0|none | 0|acc |↑ |0.7636|± |0.0332|
| - high_school_us_history | 0|none | 0|acc |↑ |0.8284|± |0.0265|
| - high_school_world_history | 0|none | 0|acc |↑ |0.8397|± |0.0239|
| - international_law | 0|none | 0|acc |↑ |0.8264|± |0.0346|
| - jurisprudence | 0|none | 0|acc |↑ |0.7130|± |0.0437|
| - logical_fallacies | 0|none | 0|acc |↑ |0.7730|± |0.0329|
| - moral_disputes | 0|none | 0|acc |↑ |0.7081|± |0.0245|
| - moral_scenarios | 0|none | 0|acc |↑ |0.2425|± |0.0143|
| - philosophy | 0|none | 0|acc |↑ |0.7267|± |0.0253|
| - prehistory | 0|none | 0|acc |↑ |0.7130|± |0.0252|
| - professional_law | 0|none | 0|acc |↑ |0.4935|± |0.0128|
| - world_religions | 0|none | 0|acc |↑ |0.8363|± |0.0284|
| - other | 1|none | |acc |↑ |0.7081|± |0.0078|
| - business_ethics | 0|none | 0|acc |↑ |0.6000|± |0.0492|
| - clinical_knowledge | 0|none | 0|acc |↑ |0.7245|± |0.0275|
| - college_medicine | 0|none | 0|acc |↑ |0.6069|± |0.0372|
| - global_facts | 0|none | 0|acc |↑ |0.3300|± |0.0473|
| - human_aging | 0|none | 0|acc |↑ |0.6726|± |0.0315|
| - management | 0|none | 0|acc |↑ |0.8252|± |0.0376|
| - marketing | 0|none | 0|acc |↑ |0.8761|± |0.0216|
| - medical_genetics | 0|none | 0|acc |↑ |0.8400|± |0.0368|
| - miscellaneous | 0|none | 0|acc |↑ |0.8161|± |0.0139|
| - nutrition | 0|none | 0|acc |↑ |0.7549|± |0.0246|
| - professional_accounting | 0|none | 0|acc |↑ |0.4929|± |0.0298|
| - professional_medicine | 0|none | 0|acc |↑ |0.6949|± |0.0280|
| - virology | 0|none | 0|acc |↑ |0.5301|± |0.0389|
| - social sciences | 1|none | |acc |↑ |0.7400|± |0.0077|
| - econometrics | 0|none | 0|acc |↑ |0.4649|± |0.0469|
| - high_school_geography | 0|none | 0|acc |↑ |0.7879|± |0.0291|
| - high_school_government_and_politics| 0|none | 0|acc |↑ |0.8705|± |0.0242|
| - high_school_macroeconomics | 0|none | 0|acc |↑ |0.6256|± |0.0245|
| - high_school_microeconomics | 0|none | 0|acc |↑ |0.6891|± |0.0301|
| - high_school_psychology | 0|none | 0|acc |↑ |0.8330|± |0.0160|
| - human_sexuality | 0|none | 0|acc |↑ |0.7328|± |0.0388|
| - professional_psychology | 0|none | 0|acc |↑ |0.7108|± |0.0183|
| - public_relations | 0|none | 0|acc |↑ |0.7091|± |0.0435|
| - security_studies | 0|none | 0|acc |↑ |0.7265|± |0.0285|
| - sociology | 0|none | 0|acc |↑ |0.8259|± |0.0268|
| - us_foreign_policy | 0|none | 0|acc |↑ |0.8500|± |0.0359|
| - stem | 1|none | |acc |↑ |0.5474|± |0.0085|
| - abstract_algebra | 0|none | 0|acc |↑ |0.3500|± |0.0479|
| - anatomy | 0|none | 0|acc |↑ |0.6444|± |0.0414|
| - astronomy | 0|none | 0|acc |↑ |0.7237|± |0.0364|
| - college_biology | 0|none | 0|acc |↑ |0.7778|± |0.0348|
| - college_chemistry | 0|none | 0|acc |↑ |0.4500|± |0.0500|
| - college_computer_science | 0|none | 0|acc |↑ |0.5700|± |0.0498|
| - college_mathematics | 0|none | 0|acc |↑ |0.3900|± |0.0490|
| - college_physics | 0|none | 0|acc |↑ |0.4216|± |0.0491|
| - computer_security | 0|none | 0|acc |↑ |0.7800|± |0.0416|
| - conceptual_physics | 0|none | 0|acc |↑ |0.5064|± |0.0327|
| - electrical_engineering | 0|none | 0|acc |↑ |0.5862|± |0.0410|
| - elementary_mathematics | 0|none | 0|acc |↑ |0.4471|± |0.0256|
| - high_school_biology | 0|none | 0|acc |↑ |0.7645|± |0.0241|
| - high_school_chemistry | 0|none | 0|acc |↑ |0.5567|± |0.0350|
| - high_school_computer_science | 0|none | 0|acc |↑ |0.6400|± |0.0482|
| - high_school_mathematics | 0|none | 0|acc |↑ |0.4148|± |0.0300|
| - high_school_physics | 0|none | 0|acc |↑ |0.4305|± |0.0404|
| - high_school_statistics | 0|none | 0|acc |↑ |0.5370|± |0.0340|
| - machine_learning | 0|none | 0|acc |↑ |0.3571|± |0.0455|
| Groups |Version|Filter|n-shot|Metric| |Value | |Stderr|
|------------------|------:|------|------|------|---|-----:|---|-----:|
|mmlu | 1|none | |acc |↑ |0.6320|± |0.0038|
| - humanities | 1|none | |acc |↑ |0.5677|± |0.0066|
| - other | 1|none | |acc |↑ |0.7081|± |0.0078|
| - social sciences| 1|none | |acc |↑ |0.7400|± |0.0077|
| - stem | 1|none | |acc |↑ |0.5474|± |0.0085|
task=leaderboard_bbh, shot=31
2
3
4
5
6
7
8lm_eval --model hf \
--model_args pretrained=meta-llama/Meta-Llama-3.1-8B,trust_remote_code=true \
--tasks leaderboard_bbh \
--device cuda:3 \
--num_fewshot 3 \
--batch_size auto \
--output_path ./harness_eval_output \
--use_cache ./harness_eval_cache/Meta-Llama-3.1-8B/llama_eval_cache
输出结果形如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28| Tasks |Version|Filter|n-shot| Metric | |Value | |Stderr|
|----------------------------------------------------------|-------|------|-----:|--------|---|-----:|---|-----:|
|leaderboard_bbh | N/A| | | | | | | |
| - leaderboard_bbh_boolean_expressions | 0|none | 3|acc_norm|↑ |0.8000|± |0.0253|
| - leaderboard_bbh_causal_judgement | 0|none | 3|acc_norm|↑ |0.5668|± |0.0363|
| - leaderboard_bbh_date_understanding | 0|none | 3|acc_norm|↑ |0.5000|± |0.0317|
| - leaderboard_bbh_disambiguation_qa | 0|none | 3|acc_norm|↑ |0.5160|± |0.0317|
| - leaderboard_bbh_formal_fallacies | 0|none | 3|acc_norm|↑ |0.5680|± |0.0314|
| - leaderboard_bbh_geometric_shapes | 0|none | 3|acc_norm|↑ |0.3400|± |0.0300|
| - leaderboard_bbh_hyperbaton | 0|none | 3|acc_norm|↑ |0.6000|± |0.0310|
| - leaderboard_bbh_logical_deduction_five_objects | 0|none | 3|acc_norm|↑ |0.3600|± |0.0304|
| - leaderboard_bbh_logical_deduction_seven_objects | 0|none | 3|acc_norm|↑ |0.3320|± |0.0298|
| - leaderboard_bbh_logical_deduction_three_objects | 0|none | 3|acc_norm|↑ |0.5160|± |0.0317|
| - leaderboard_bbh_movie_recommendation | 0|none | 3|acc_norm|↑ |0.8080|± |0.0250|
| - leaderboard_bbh_navigate | 0|none | 3|acc_norm|↑ |0.4960|± |0.0317|
| - leaderboard_bbh_object_counting | 0|none | 3|acc_norm|↑ |0.4920|± |0.0317|
| - leaderboard_bbh_penguins_in_a_table | 0|none | 3|acc_norm|↑ |0.4384|± |0.0412|
| - leaderboard_bbh_reasoning_about_colored_objects | 0|none | 3|acc_norm|↑ |0.3760|± |0.0307|
| - leaderboard_bbh_ruin_names | 0|none | 3|acc_norm|↑ |0.5240|± |0.0316|
| - leaderboard_bbh_salient_translation_error_detection | 0|none | 3|acc_norm|↑ |0.4040|± |0.0311|
| - leaderboard_bbh_snarks | 0|none | 3|acc_norm|↑ |0.6236|± |0.0364|
| - leaderboard_bbh_sports_understanding | 0|none | 3|acc_norm|↑ |0.7400|± |0.0278|
| - leaderboard_bbh_temporal_sequences | 0|none | 3|acc_norm|↑ |0.0840|± |0.0176|
| - leaderboard_bbh_tracking_shuffled_objects_five_objects | 0|none | 3|acc_norm|↑ |0.1480|± |0.0225|
| - leaderboard_bbh_tracking_shuffled_objects_seven_objects| 0|none | 3|acc_norm|↑ |0.1160|± |0.0203|
| - leaderboard_bbh_tracking_shuffled_objects_three_objects| 0|none | 3|acc_norm|↑ |0.3480|± |0.0302|
| - leaderboard_bbh_web_of_lies | 0|none | 3|acc_norm|↑ |0.4880|± |0.0317|
task=agieval_en, shot=3
1 | |
结果形如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26| Tasks |Version|Filter|n-shot| Metric | |Value | |Stderr|
|---------------------------------|------:|------|-----:|--------|---|-----:|---|-----:|
|agieval_en | 0|none | |acc |↑ |0.3141|± |0.0071|
| - agieval_aqua_rat | 1|none | 3|acc |↑ |0.2244|± |0.0262|
| | |none | 3|acc_norm|↑ |0.2244|± |0.0262|
| - agieval_gaokao_english | 1|none | 3|acc |↑ |0.5752|± |0.0283|
| | |none | 3|acc_norm|↑ |0.5065|± |0.0286|
| - agieval_logiqa_en | 1|none | 3|acc |↑ |0.3011|± |0.0180|
| | |none | 3|acc_norm|↑ |0.3011|± |0.0180|
| - agieval_lsat_ar | 1|none | 3|acc |↑ |0.2043|± |0.0266|
| | |none | 3|acc_norm|↑ |0.1826|± |0.0255|
| - agieval_lsat_lr | 1|none | 3|acc |↑ |0.3569|± |0.0212|
| | |none | 3|acc_norm|↑ |0.2569|± |0.0194|
| - agieval_lsat_rc | 1|none | 3|acc |↑ |0.5242|± |0.0305|
| | |none | 3|acc_norm|↑ |0.3123|± |0.0283|
| - agieval_math | 1|none | 3|acc |↑ |0.1490|± |0.0113|
| - agieval_sat_en | 1|none | 3|acc |↑ |0.5146|± |0.0349|
| | |none | 3|acc_norm|↑ |0.3058|± |0.0322|
| - agieval_sat_en_without_passage| 1|none | 3|acc |↑ |0.3835|± |0.0340|
| | |none | 3|acc_norm|↑ |0.2767|± |0.0312|
| - agieval_sat_math | 1|none | 3|acc |↑ |0.3500|± |0.0322|
| | |none | 3|acc_norm|↑ |0.2818|± |0.0304|
| Groups |Version|Filter|n-shot|Metric| |Value | |Stderr|
|----------|------:|------|------|------|---|-----:|---|-----:|
|agieval_en| 0|none | |acc |↑ |0.3141|± |0.0071|
parallelize=True 多GPU
llama3.1-8b-instruct, task=leaderboard_gpqa, shot=0
这个任务如果使用下面代码, 因为一个GPU放不下, 数据太多, 会报错‘torch.OutOfMemoryError: CUDA out of memory.’:1
2
3
4
5
6
7lm_eval --model hf \
--model_args pretrained=meta-llama/Meta-Llama-3.1-8B-Instruct,trust_remote_code=true \
--tasks leaderboard_gpqa \
--device cuda:2 \
--batch_size auto \
--output_path ./harness_eval_output \
--use_cache ./harness_eval_cache/Meta-Llama-3.1-8B-Instruct/llama_eval_cache
可以使用下面代码, 添加parallelize=True(parallelize让数据分布在多个gpu中计算, 尽管下面指定的device只有一个.), 注意model_args后面的三个参数的逗号之间没有空格, 否则会报错:1
2
3
4
5
6
7lm_eval --model hf \
--model_args pretrained=meta-llama/Meta-Llama-3.1-8B-Instruct,parallelize=True,trust_remote_code=True \
--tasks leaderboard_gpqa \
--batch_size auto \
--device cuda:2 \
--output_path ./harness_eval_output \
--use_cache ./harness_eval_cache/Meta-Llama-3.1-8B-Instruct/llama_eval_cache
输出结果:1
2
3
4
5
6| Tasks |Version|Filter|n-shot| Metric | |Value | |Stderr|
|----------------------------|-------|------|-----:|--------|---|-----:|---|-----:|
|leaderboard_gpqa | N/A| | | | | | | |
| - leaderboard_gpqa_diamond | 1|none | 0|acc_norm|↑ |0.3182|± |0.0332|
| - leaderboard_gpqa_extended| 1|none | 0|acc_norm|↑ |0.3095|± |0.0198|
| - leaderboard_gpqa_main | 1|none | 0|acc_norm|↑ |0.3438|± |0.0225|
accelerate加速, 多GPU
task=leaderboard_math_hard, shot=0
对这个任务分别使用原始单个gpu, accelerate加速, 和parallelize=True.
单个gpu:1
2
3
4
5
6
7lm_eval --model hf \
--model_args pretrained=meta-llama/Meta-Llama-3.1-8B-Instruct,trust_remote_code=true \
--tasks leaderboard_math_hard \
--device cuda:1 \
--batch_size auto \
--output_path ./harness_eval_output \
--use_cache ./harness_eval_cache/Meta-Llama-3.1-8B-Instruct/llama_eval_cache
parallelize=True 多gpu:1
2
3
4
5
6
7lm_eval --model hf \
--model_args pretrained=meta-llama/Meta-Llama-3.1-8B-Instruct,parallelize=True,trust_remote_code=True \
--tasks leaderboard_math_hard \
--device cuda:1 \
--batch_size auto \
--output_path ./harness_eval_output \
--use_cache ./harness_eval_cache/Meta-Llama-3.1-8B-Instruct/llama_eval_cache
accelerate多gpu:
首先创建config.yml文件:1
accelerate config
按照步骤填写, gpu-ids如果指定多个gpu, 需要用逗号分开, 不要添加括号. e.g. 0,1,2,3 填写完会保存config.yml文件. 然后运行:1
2
3
4
5
6
7accelerate launch -m lm_eval --model hf \
--model_args pretrained=meta-llama/Meta-Llama-3.1-8B-Instruct,trust_remote_code=true \
--tasks leaderboard_math_hard \
--batch_size auto \
--device cuda:2 \
--output_path ./harness_eval_output \
--use_cache ./harness_eval_cache/Meta-Llama-3.1-8B-Instruct/llama_eval_cache
输出结果:1
2
3
4
5
6
7
8
9
10| Tasks |Version|Filter|n-shot| Metric | |Value | |Stderr|
|---------------------------------------------|-------|------|-----:|-----------|---|-----:|---|-----:|
|leaderboard_math_hard | N/A| | | | | | | |
| - leaderboard_math_algebra_hard | 1|none | 4|exact_match|↑ |0.2606|± |0.0251|
| - leaderboard_math_counting_and_prob_hard | 1|none | 4|exact_match|↑ |0.0569|± |0.0210|
| - leaderboard_math_geometry_hard | 1|none | 4|exact_match|↑ |0.0530|± |0.0196|
| - leaderboard_math_intermediate_algebra_hard| 1|none | 4|exact_match|↑ |0.0143|± |0.0071|
| - leaderboard_math_num_theory_hard | 1|none | 4|exact_match|↑ |0.0844|± |0.0225|
| - leaderboard_math_prealgebra_hard | 1|none | 4|exact_match|↑ |0.2902|± |0.0328|
| - leaderboard_math_precalculus_hard | 1|none | 4|exact_match|↑ |0.0370|± |0.0163|
accelerate和parallelize=True两种方法是二选一的, 都是使用多个GPU并行计算. 但是在我的尝试里面, 使用accelerate或者parallelize都挺慢的, 和原始只使用1个gpu一样慢.
注意: 我上面的输出结果只是给大家看看这个task任务的输出是什么形式, 尽管上面的结果是我真实运行得到的, 但和llama3.1的evaluation部分的数据有一定差距, 我认为可能是因为使用lm-eval-harness第三方库调用的数据和llama3.1官方使用的数据有差别, 或者llama3.1的eval details和tricks我没有实现.
资料链接
github meta-llama: https://github.com/meta-llama/llama-models/tree/main
官方给出了Llama3.1的Model_card, 和eval_details.
lm-evaluate-harness工具的使用: 如何使用lm-evaluation-harness零代码评估大模型, Medium-LLM评估教学.