综述大模型的参数高效微调(PEFT)方法
本文最后更新于 2024年8月19日下午3点09分
综述PEFT方法
PEFT, 全称Parameter-Efficient Fine-tuning, 是大模型的参数高效微调方法.
PEFT方法只需要微调LLM的少量参数, 不需要对预训练模型的全部参数进行微调. 可以极大降低大模型微调的计算和存储成本, 并且有助于模型的轻便型, 便于部署在消费级硬件上. PEFT方法可以获得和全参数微调相近的性能, 能使预训练大模型高效适用于各种下游任务.
1. 为什么需要PEFT:
现在的大语言模型(LLM), 例如Llama系列, GPT系列, BERT等模型, 动辄有上亿的参数. 这些大模型在自然语言处理(NLP), 计算机视觉(CV), 音频等方面有突出表现. 对一个预训练好的LLM, 可以直接使用(比如zero-shot零样本推理), 也可以在下游任务上进行微调(fine-tuning). 对某一个特定的任务, 在这个下游任务数据集上进行微调可以获得更好的性能.
但是模型变得越来越大, 在消费级硬件上直接对全部参数微调变得不现实, 因为微调模型和原始预训练模型的大小相同. 比如llama3-405B模型, 有405 billion个参数, 模型大小有820G, 部署成本很高, 光是把pre-trained模型下载就需要820G的磁盘空间, 后续如果微调全部参数, 在个人GPU上基本是无法实现的.
参数高效微调(PEFT)方法就是为了让人们更方便更快速的微调大模型. PEFT方法只微调少量(或者额外)模型参数, 冻结预训练LLM的大部分参数, 大大降低计算和存储成本. 也能克服‘灾难性遗忘’问题.
并且PEFT还有助于模型轻便性, 全参数微调的checkpoint很大(高达几十GB), 但是PEFT方法得到的checkpoint只有几MB.
PEFT还可以对预训练LLM添加额外的含有少量训练参数的层, 只对额外层的参数进行训练, 无需改动整个模型. 最典型的就是LoRA方法.
灾难性遗忘问题:
这是在LLM全参数微调期间观察到的现象.
2. 常见的PEFT方法
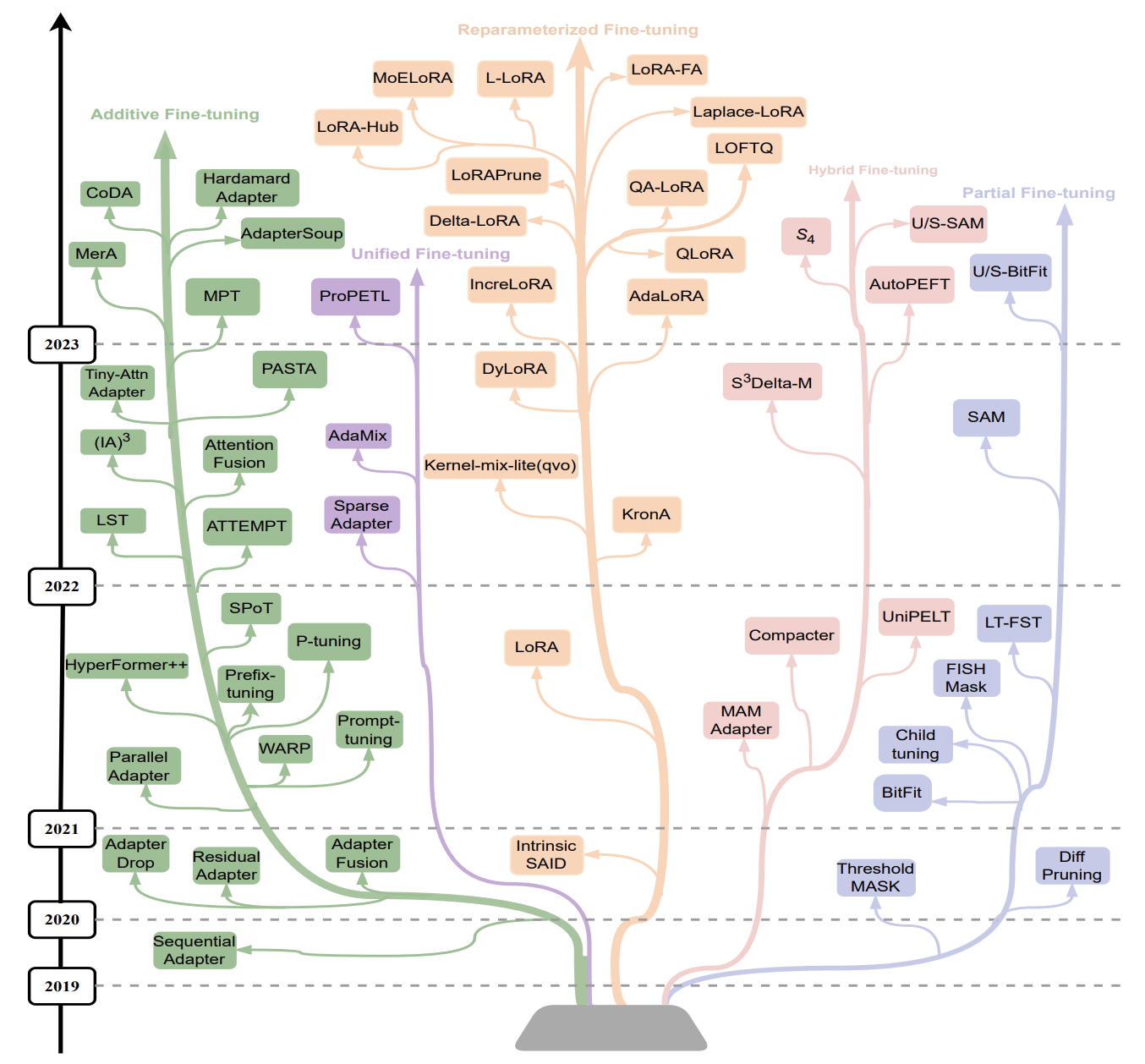
目前, PEFT方法分为五大类:
- Additive Fine-tuning: 给预训练模型添加额外的参数或者层, 只微调训练这些新增的参数或者层. Additive分为两大类:
1.1 Adapter: 在transformer子层后面加一个小的全连接层, 只微调新加入的全连接层参数. 典型论文: Sequential Adapter
1.2 Soft Prompts: 常见的prompts方法是在输入中构造prompts模板. soft prompts直接在输入的embedding中加入向量作为soft prompts, 并对这些向量参数进行微调, 不需要构造prompts模板. 典型论文: Prefix-tuning, Promp-tuning. - Reparameterized Fine-tuning: 利用低秩表征(low-rank representation)来最小化可训练的参数, 因为大量参数中仅有一小部分起到关键作用, 在这个起到关键作用的自空间中寻找参数进行微调. 典型论文: LoRA. LoRA算是目前最常用的PEFT方法, 其变形还有QLoRA, AdaLoRA等.
- Partial Fine-tuing: 对模型的部分层(例如最后几层)的权重参数或者偏置项进行微调. 典型论文: BitFit
- Hybrid Fine-tuning: 混合多种方法的PEFT. 典型论文: MAM Adapters
- Unified Fine-tuning: 通过统一的框架来微调模型, 让微调更加系统化规范化. 典型论文: SparseAdapter
3. PEFT和quantization技术
PEFT是一种高效的参数微调的方法, 上面介绍了PEFT的细分方法和发展. 实际上在使用PEFT时, 我们还会结合其他方法, 比如quantization量化, prompt-tuning, pruning剪枝等.
- Quantization量化: 量化就是把模型的浮点型参数(例如FP16, FP32)转为低精度参数(例如int4,int8)等, 减少模型存储空间和计算量.
- Prompt-tuning: 对模型输入添加一些特殊提示符(prompts)来优化模型输出. 该方法不需要改变模型参数, 只在输入时添加一些文本信息, 引导模型输出期望文本. 该方法简单高效, 还不用微调模型参数. 由此引申出prompt engineering岗位. 因为, 例如GPT系列模型参数量很大, 它的能力很大但需要合理的输入来引导挖掘, 只是一个简单的输入不能完美挖掘其能力, 导致输出的结果不理想. 在prompt中输入更完善的信息引导模型的输出, 可能比微调模型的效果更好.
- Pruning剪枝: 剪枝会删除模型中一些不必要参数, 来减少模型规模. 有些参数对模型没有贡献, 是冗余参数, 通过pruning删除. Pruning能减小模型规模.
参考和资源链接:
参考博客: CSDN-大模型高效微调方法大全, huggingface-PEFT
参考这个论文: Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models: A Critical Review and Assessment