基于深度学习的光流算法及代码
本文最后更新于 2025年5月5日下午12点35分
深度学习的光流模型
在前一篇博客‘传统光流算法和代码’, 我介绍了传统光流算法: 1981年的LK算法, 金字塔光流方法, 和forneback算法. 随着深度学习的快速发展, 2015年有作者提出FlowNet模型, 并在2017年提出FlowNet2.0版本, 至今仍是深度学习光流估计算法中最经典的论文.
光流概念的介绍
在计算机视觉中, 光流指的是视频中物体的移动. 具体地, 是视频图像的一帧中相同物体像素点移动到下一帧的移动量, 用二维向量表示. 稀疏光流会对图像中特征明显的关键点进行光流追踪, 而稠密光流会对图像所有像素点进行光流追踪.
稠密光流中每个像素的运动大小和方向, 会用不同的颜色和亮度表示. 下图展示的是光流和颜色的映射关系.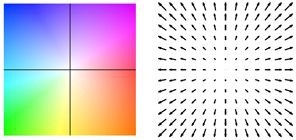
在传统光流追踪算法中, 有两个很重要的假设, 首先是亮度不变假设, 估计光流的两帧图像中, 同一个物体的亮度是不变的;第二个假设是领域光流相似假设, 在一个小的图像区域(通常是$3* 3$或者$5* 5$ patch), 里面的像素移动方向和大小基本一致.
ICCV2015提出的FlowNet是最早的使用CNN解决光流估计问题的算法, 在CVPR2017同一团队提出了FlowNet2.0, 下面我会介绍这两种模型的原理.
FlowNet模型
FlowNet模型是CNN结构, 输入是待估计光流的两帧图像, 输出是图像每一个像素点的光流.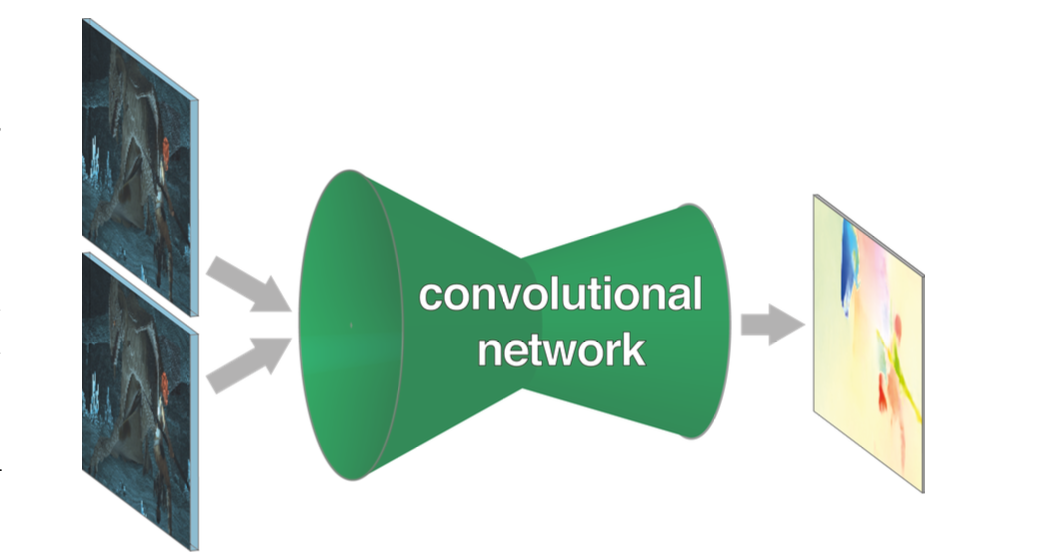
Loss函数
模型的Loss是预测光流和GroundTruth之间的欧式距离, 即EPE(end-point error). GroundTruth是图像的真实光流值, 但是人工标注的光流几乎不可能, 因此本论文提出一种GT光流的生成方法. 该方法会对图像做仿射变换, 生成对应的图像, 这样就能得到两帧图像和其GT光流, 以此作为训练数据集来训练模型. 为了模拟图像中存在的多种运动状态, 作者将虚拟的椅子叠加到背景图像中, 并同时对背景图和椅子坐不同的仿射变换得到另一张图. 以此构建flyingChairs训练数据集. flyingchairs训练数据包含22,872对合成图片和对应的真实光流.

仿射变换的原理和实现
仿射变化是一种保持对应物体之间‘共线性’和‘比例关系’的线性变换, 常见操作有: 平移translation, 缩放scaling, 旋转rotation, 剪切shearing. 可以用矩阵操作表达:
可以使用python opencv直接实现:1
2
3M = cv2.getRotationMatrix2D(center=(w//2, h//2), angle=10, scale=1.0)
M[:, 2] += [tx, ty]
img_transformed = cv2.warpAffine(img, M, (w, h))
第一步cv2.getRotationMatrix2D获得仿射矩阵, 其中center设置旋转中心点, angle是旋转角度, scale缩放因子. 然后M[:, 2] += [tx, ty]对仿射矩阵M添加平移操作. 最后在输入图像img上应用M仿射矩阵, (w, h)是输出图像的尺寸, 得到仿射变换后的图像img_transformed.
模型结构
作者提出了两种FlowNet模型结构, 分别是FlowNetSimple和FlowNetCorr(correlation), 这两种模型在encoder模块(降维)不同, 在decoder模块(升维)相同.
FlowNetSimple对输入的两个图片, 会简单地将它们拼接在一起, 即两张$h\times w \times 3$的图片拼接为一个$h\times w \times 6$的tensor, 作为CNN encoder的输入. 然后通过多个卷积层进行降维, 然后通过refinement(也就是decoder结构)的反卷积进行升维,得到预测的光流图像.
在FlowNetCorr结构中, 先对两个图像分别卷积, 获得高维feature, 然后进行相关运算把信息合并, 然后进行卷积再反卷积得预测光流.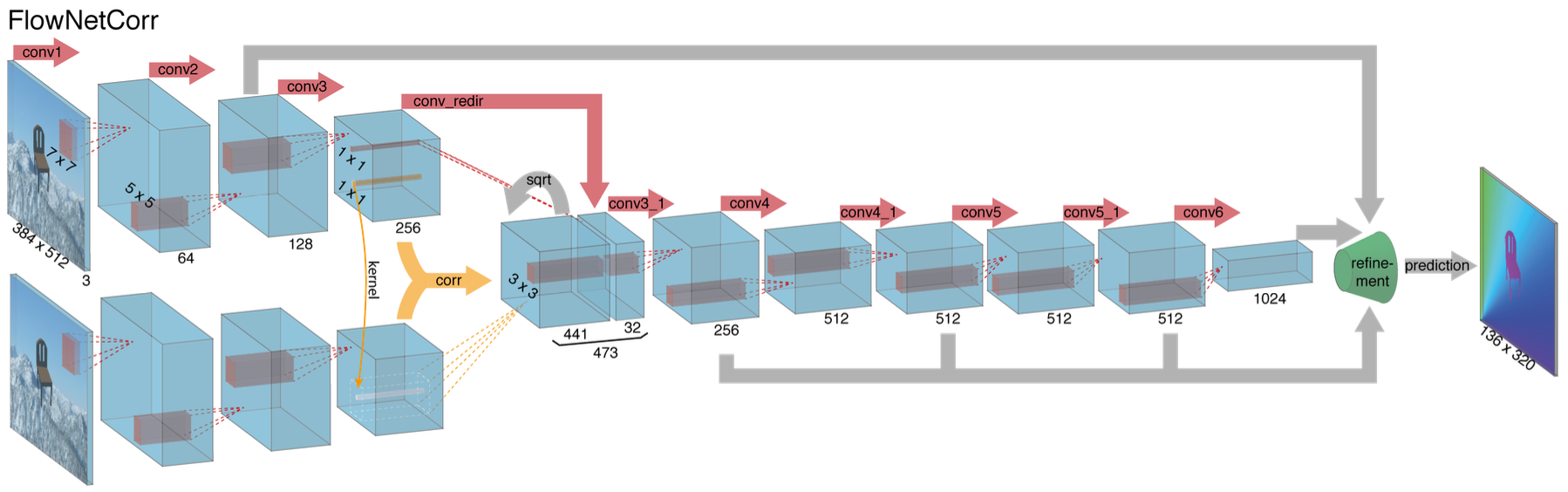
在decoder结构, 也就是refinement部分, 每层的反卷积包含三个输入, 一是上一层反卷积的输出(高层语意信息), 二是encoder对应层的featuremap(低层信息), 三是前一层输出的coarse光流上采样. 这种方法融合高低层信息, 也引入了coarse-to-fine机制.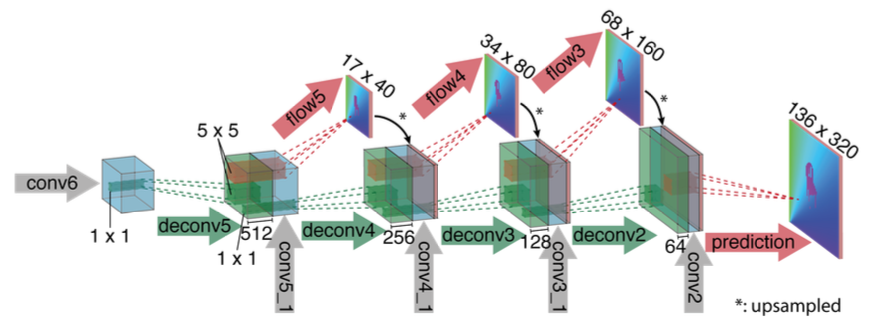
FlowNet2.0模型
Flownet2.0堆叠了多个FlowNet网络, 并解决了FlowNet的小偏移(small displacement)不准确问题.
小偏移不准确问题(small displacement bias)就是光流方法在检测微小像素移动时精度下降的问题.
Flownet2.0的输入, 不仅仅是两张图片, 而是五个图: img1,img2,前一个模块的预测光流, warped图, 亮度误差(brightness error). 其中warped图就是将预测光流作用在img2上, 还原像素位移, 让其每个像素点尽量与img1对齐. 但是warped图和img1还是会有差距, 因为预测光流不准确, img1减去warped图就是亮度误差图. 将这五个图叠加的tensor输入给后续模块.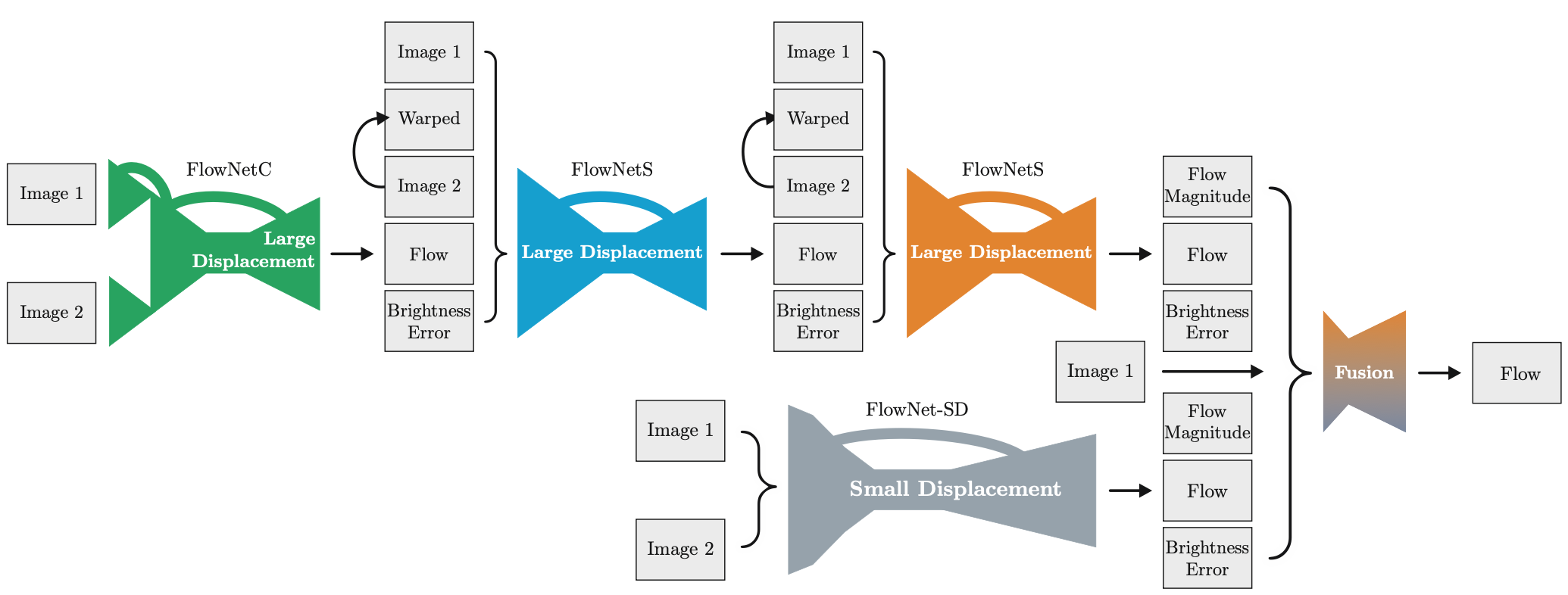
RAFT模型
论文“RAFT: Recurrent All-Pairs Field Transforms for Optical Flow”是ECCV 2020的best paper, 用于光流估计的深度学习模型.
RAFT分为三个模块:
- Feature Extractor 特征提取模块 & Context Extractor 语义特征提取模块. 特征提取模块逐像素地提取两张图片的特征,而语义特征提取模块架构与特征提取是一样的,但是只对一个模块进行提取.
- Visual Similarity Calculator 相似性计算模块
- Updator 更新迭代模块
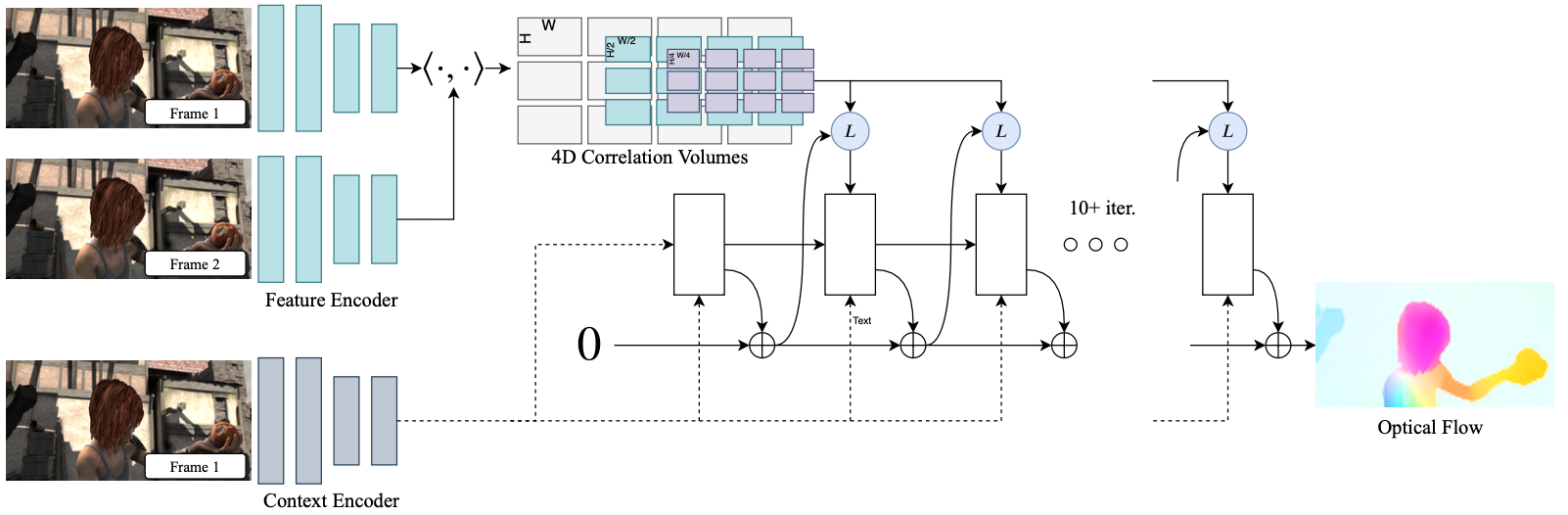
特征提取模块
首先对两个图片进行特征提取, 映射为$\frac{1}{8}$分辨率的downsample feature map. 也就是对图像下采样卷积, 让H和W变为原来的八分之一, 增大特征通道的维度为256, $R^{H \times W \times 3} \rightarrow R^{\frac{H}{8} \times \frac{W}{8} \times D}$. 此外还有语义提取器, 结构和特征提取器一样, 但只对第一张图片提取信息.
计算相似性
在得到两个图像的dowmsample featuremaps后, 构建一个大小为 $H\times W\times H \times W$ 的四维相关体,代表图像 1 中每个像素和图像 2 中所有像素的相似度。
参考:
[1] 光流估计—从传统方法到深度学习
[2] ECCV 2020 Best Paper Award | A New Architecture For Optical Flow
[3] Perceiver IO: a scalable, fully-attentional model that works on any modality
[4] Motion Estimation with Optical Flow: A Comprehensive Guide